 On l’a déjà dit (discrètement) ici : Siffler en travaillant mais je pense qu’il faut arrêter d’être discret quand les développeurs partent dans la Silicon Valley pour l’argent alors qu’on peut rester en France et vivre très bien aussi ! Et quand je dis très bien, je veux dire : vraiment très bien. En doublant nos revenus, on ne double pas simplement notre pouvoir d’achat, mais on le multiplie par 10 !
On l’a déjà dit (discrètement) ici : Siffler en travaillant mais je pense qu’il faut arrêter d’être discret quand les développeurs partent dans la Silicon Valley pour l’argent alors qu’on peut rester en France et vivre très bien aussi ! Et quand je dis très bien, je veux dire : vraiment très bien. En doublant nos revenus, on ne double pas simplement notre pouvoir d’achat, mais on le multiplie par 10 !
Prenons un exemple simple, tu es développeur Java junior à Paris, Tu gagnes environ 2500€ net par mois. Pas mal ! Mais après avoir payé ton loyer parisien, ton abonnement de transport, tes impôts, tes courses et les billets de trains pour aller voir Maman de temps en temps, il te reste combien ? 200€ 300€ ? Imagine maintenant que tu gagnes 5000€ net par mois. Tu vas payer plus d’impôts certes mais grosso modo, il te restera tout de même environ 2500€ à la fin du mois, soit 10x plus qu’avant. Rien que ça. Et pour l’avoir vécu, c’est juste énorme. Et non, je crois que tu ne te rends pas compte. Tu ne te rends pas compte de ce que c’est de ne pas savoir combien t’ont coûté tes courses, de répondre tout le temps « bof, ça va » quand quelqu’un te dit « Mais c’est super cher ! » ou encore de regarder ton compte en te disant « Mais pourquoi j’ai autant d’argent ? »
Oouhaa ouhaaa…. cool alors c’est quoi la recette miracle ? Elle est très simple : passer freelance. Tu peux calculer tes futurs revenus sur la Calculatrice freelance ou à la suite en fonction de ton expérience :
- Débutant : Ancien salaire net moyen : 2000€. Tarif journalier moyen : 320€ (=4000€ net de revenus en indépendant)
- Junior : Ancien salaire net moyen : 2500€. Tarif journalier moyen : 400€ (=5000€ net de revenus en indépendant)
- Expérimenté : Ancien salaire net moyen : 3000€. Tarif journalier moyen : 500€ (=6000€ net de revenus en indépendant)
Bien évidemment je compare ce qui est comparable, les montants donnés sont bien ceux que tu indiqueras dans la case « Traitements et salaires » de ta déclaration de revenus. Et en plus la réalité est encore plus drôle pour le freelance, mais n’en rajoutons pas avec cet iPhone 6 à 900€ que tu vas payer hors taxes et hors charges via ta société sous prétexte que tu expérimentes le développement mobile.
Vous en doutez ? Et vous avez raison, les freins psychologiques sont nombreux au passage en freelance : Comment trouver un client ? Et si le client refuse de me payer ? Et la comptabilité ? Je me suis posé les mêmes questions ! Et je peux vous rassurer tout de suite, toutes les personnes que je connais qui ont eu la folie d’y aller vous diront pareil que moi : C’est plus simple que ce qu’on s’imagine et plus jamais je ne ferai marche arrière ! Comme toi, nous étions (et sommes restés) simplement développeur sans autre compétence que celle de savoir coder.
Edit 2017 :
Plus aucune raison de ne pas se lancer, trouver une mission est devenu très facile avec des sites comme Hopwork pour capitaliser sur sa réputation ou Tiime pour la comptabilité !
]]>
Si on considère la classe Color qui comporte 2 méthode : une qui change les 2 champs preferedColor et colorOfMyDress avec la même couleur donnée en paramètre et une qui affiche les 2 champs.
public class Color {
public String preferedColor;
public String colorOfMyDress;
public void changeColor(String color) {
preferedColor = color;
colorOfMyDress = color;
}
public void printColor() {
System.out.println("Ma couleur préferée est le " + preferedColor + " et la couleur de ma robe est " + colorOfMyDress);
}
}
Imaginons une classe AuroreColor qui ressemble à celle la et que cette classe soit utilisée dans une appli web, et l’on souhaite que tous les utilisateurs puissent modifier la couleur qui est partagée entre tous :
public class AuroreColor {
public Color color;
...
}
Chaque utilisateur peut changer la couleur via une interface et en réponse, s’affiche le texte affiché par la méthode printColor(). Si Paul choisit et valide la couleur rouge, alors il voit à l’écran : « Ma couleur préferée est le rouge et la couleur de ma robe est rouge. »
Mais si 2 utilisateurs utilisent en même temps cette fonctionnalité, on peut obtenir des résultats « non attendus » comme « Ma couleur préferée est le vert et la couleur de ma robe est jaune », alors qu’on s’attends à ce que les 2 champs soient identiques.
En effet, il est (entre autre) possible que au même moment, les threads associés à chacun des utilisateurs soient au même moment au sein de la méthode changeColor, impliquant que pour un laps de temps très court, les 2 paramètres sont modifiés et ont des valeurs différentes. C’est particulièrement visualisable si on reprends l’exemple d’un counter :
public class Counter {
double counter;
public void increment() {
counter++;
}
public double getCounter() {
return counter;
}
}
On essaie de compter le nombre de mots d’un livre mais on se rends compte que le résultat n’est pas toujours correct. La cause est assez simple : counter++ marche de la façon suivante :
– Je récupère la valeur de counter
– J’ajoute 1
– J’affecte le résultat à counter
Si 2 threads accèdent l’un après l’autre à ce code, pas de problème. Par contre, si 2 threads appelent la méthode incrémente dans un laps de temps très court, alors il est possible qu’ils utilisent la même valeur de counter lors de l’incrémentation, alors, chacun va faire un +1, sur la même valeur et réassignée cette valeur à counter. Ainsi, on aura au final, counter = 1 alors que l’un après l’autre, on voit bien counter = 2.
En séquence on aura :
Thread 1 :
Valeur de counter initial : 0
Valeur après incrémentation : 1
Thread 2 :
Valeur de counter initial : 1
Valeur après incrémentation : 2
Soit un résultat final de 2
En parrallèle, on peut avoir :
Thread 1 :
Valeur de counter initial : 0
Valeur après incrémentation : 1
Thread 2 :
Valeur de counter initial : 0
Valeur après incrémentation : 1
Soit un résultat final de 1
Il y a plusieurs manières de résoudre ce problème. L’un d’elle serait de garantir que 2 threads ne puissent pas accéder en même temps à la méthode changeColor (ou increment) en utilisant le mot clé synchronized sur cette méthode . Si on reprends les explications pour une méthode synchronized :
- First, it is not possible for two invocations of synchronized methods on the same object to interleave. When one thread is executing a synchronized method for an object, all other threads that invoke synchronized methods for the same object block (suspend execution) until the first thread is done with the object.
- Second, when a synchronized method exits, it automatically establishes a happens-before relationship with any subsequent invocation of a synchronized method for the same object. This guarantees that changes to the state of the object are visible to all threads.
Pour faire plus simple, le mot clé synchronized sur une méthode garantit que cette dernière ne sera exécutée qu’un par au plus un thread, les autres attendant que le premier ait finit.
public class Color {
public String preferedColor;
public String colorOfMyDress;
public synchronized void changeColor(String color) {
preferedColor = color;
colorOfMyDress = color;
}
public void printColor() {
System.out.println("Ma couleur préferée est le " + preferedColor + " et la couleur de ma robe est " + colorOfMyDress);
}
}
En modifiant de la sorte, 2 threads ne pourront jamais modifier en même temps les couleurs, mais seulement l’un après l’autre. Mais il y a un mais, car cela ne marche pas et cela fait partie des erreurs que l’on retrouve souvent 
]]>

Déjà eu envie de faire de l’open-source mais ne sachant pas comment débuter ? Vous avez un projet open-source et cherchez un coup de main ? Quelque soit votre situation, le Hackergarten qui aura lieu mercredi après midi lors de Devoxx France est LE lieu où il faut être, vous y trouverez des commiteurs qui vous accompagnerons pour faire votre premier commit open-source sur un des projets représentés ! Organisé par Brice Dutheil et Mathilde Lemée, c’est un bon moyen de progresser et de se rendre utile.
Hackergarten c’est le rendez-vous des gens qui veulent participer aux projets opensource. L’idée c’est, dans un format de 3h, de contribuer un logiciel, un fix, un feature, une documentation dont d’autres pourraient avoir l’usage. Il s’articule autour de commiters actifs pour mentorer les hackers qui participent à l’évènement.
Bref que du bon.
Voilà la liste des projets qui seront représentés :
- Achilles
- FluentLenium
- CRaSH
- Ceylon
- Apache Maven
- Jenkins
- Restx
- Voxxrin
- Hibernate OGM
- Hibernate Search
- EasyMock
- Objenesis
- Spek
- et d’autres à venir !
La liste n’est pas fixée, commiters, vous pouvez vous ajouter ici ! Il vous faudra venir avec votre portable et n’hésitez pas à regarder les pré-requis pour pouvoir démarrer plus rapidement !
]]>
Sérieusement, on est en train de révolutionner le monde des intermédiaires sans foi ni loi. En quelques mots :
- Le site est entièrement gratuit tant qu’on n’a pas un devis accepté.
- La commission est 3 fois moins importante qu’un intermédiaire classique (moins de 10% pour Hopwork contre 15%-25% actuellement)
- On peut contractualiser en direct (ou pas, à vous de choisir)
- Les freelances sont « approuvés » par leurs pairs et par leurs clients
Pas de ticket d’entrée
Non mais allô quoi, payer pour chercher un développeur ou une mission alors qu’on n’est pas sûr de trouver un deal ? Ça gave ! Hopwork prend clairement le modèle d’Airbnb, on cherche autant qu’on veut, on ne paye que si on trouve !
Commission raisonnée
Quand un intermédiaire classique prend facilement 20% si ce n’est plus, Hopwork ne prendra que 9% sur des missions courtes et ce sera bientôt dégressif en fonction du volume. Quoi de plus logique ? On paye la mise en relation, c’est ce qui a le plus de valeur, ensuite on paye le service (facturation, paiement, litige, recommandations clients etc.)
Contractualisation en direct
Là aussi, franchement en tant que freelance, je ne veux pas avoir une 3ème personne dans la relation, qui a des intérêts potentiellement divergents des miens. Et pour le client qui souhaite pouvoir parler à quelqu’un d’autre que le freelance pour des raisons qu’on peut imaginer aisément (notamment en cas de litige), le service client d’Hopwork est là pour ça !
Freelances approuvés
En plus de la localisation, le moteur de recherche met en avant les freelances qui ont le plus de recommandations et le plus de commentaires satisfaisants des clients. Un gage de sécurité pour le client et un bon moyen de se mettre en avant et d’augmenter son business pour les meilleurs d’entre nous !
Garantie de paiement
Pour les missions courtes, le client déposera un acompte sur un compte de séquestre. Pour une mission longue, Hopwork se chargera du recouvrement. Zéro tracas, Zéro blabla pour reprendre une pub bien connue
Nouveaux clients
Les clients sont souvent verrouillés par les SSII et autres intermédiaires (qui en profitent bien en passant pour faire de belles marges mais passons). Hopwork déverrouille ces clients en ce faisant référencer pour vous. Et va même plus loin en entrant chez certains clients réputés pour ne pas prendre de freelances ! Et n’oubliez pas, vous contractualisez avec le client, ouf non ?
Elle est où l’arnaque ?
L’astuce est dans le contrat que vous faites avec Hopwork, en vous inscrivant sur Hopwork, vous vous engagez à payer la mise en relation à Hopwork. Hopwork vous enverra une facture pour chaque mise en relation.
Quoi encore une facture à payer ? relou !!
Non pas relou, le client vous paye en passant par la plateforme de paiement Hopwork. (Virement ou CB) Ensuite Hopwork vous envoie votre part défalqué de la commission. Comptablement vous avez fait 100% du CA et payé une prestation de mise en relation. Toutes les factures sont générées et disponibles à tout moment. Vous n’avez rien de fait de plus que d’habitude. : Zéro tracas, Zéro blabla !
Alors, bonne idée ? Allez-vous nous rejoindre sur Hopwork et participer à l’aventure ?
]]>Une des grandes idées des architectures orientées data (Buzz words : OpenData, BigData) est de laisser la possibilité de poser des questions, inconnues aujourd’hui mais qui pourront s’exécuter demain sur les données d’aujourd’hui. Pour cela il suffit “simplement” de stocker les données plutôt qu’un état (calculé à partir des données).
Qu’est ce que la data ?
Une idée reçue est que la data est ce qui est stocké en base de données. Voici un exemple simple d’interaction avec un site web :

La data, (ou les données) sont toutes les informations immuables que nous pouvons récolter, dans cette exemple il s’agit des actions exercées sur notre site. Les données, ce sont des faits, des vérités, et non pas des états calculés.
Cas d’utilisation des data
Dans une application classique, seul l’état est stocké en base, et il est possible de poser des questions au système, par exemple : combien il y a t’il de profils sur mon site ? Qui est coach Agile ? etc.
En revanche, certaines questions seront impossibles à poser au système ou retourneront un résultat erroné :
-
Combien de personnes connaissent Java ? (L’info est perdu pour Vincent).
-
Combien de commentaires Vincent à t’il reçu ? ( 2 en réalité)
-
Qui crée des profils factices pour augmenter artificiellement son nombre de commentaires ? (Pour cette question il faudrait stocker des informations techniques et faire des recoupements, conserver une trace des comptes supprimés etc..)
Et, plus amusant des questions utilisant des données externes, telle que la météo par exemple :
-
Quel temps fait il le plus souvent lorsqu’un profil et créé ? Lorsqu’il est supprimé ?
Ce genre de questions peutt être utile pour des scientifiques dans des domaines tels que l’anthropologie !
Ou pas ! En réalité, il est difficile de prévoir comment les données vont être utilisées demain. Peut être pour proposer une fonctionnalité de recommendation poussée, ajouter une nouvelle statistique pour analyser les futures campagnes marketing d’Hopwork par exemple… Qui sait ? Ce que nous savons en revanche, c’est qu’il faut absolument, non pas stocker simplement un état calculé mais bien l’ensemble des données du site afin de pouvoir nous en servir dans le futur.
Mise en oeuvre technique
Pour mettre en oeuvre nos cas d’usages et les cas d’utilisations futurs et encore inconnus, nous allons rencontrer de nombreux problèmes techniques :
-
Stockage des données : Stocker l’ensemble des faits plutôt qu’un état demande beaucoup plus d’espace de stockage et cet espace augmente constamment dans le temps même si la base des utilisateurs reste fixe. Elle augmente donc à la fois dans le temps et en fonction du nombre d’utilisateur et aussi du nombre de fonctionnalités qui s’ajoute au fur et à mesure de la vie d’une application.
-
Performance lors du requêtage : Une base de données de faits n’est pas optimisé pour poser des questions. Par exemple, pour connaître le nombre de commentaires visibles de Vincent nous sommes obligé de relire tous les faits liés à Vincent. Et ce nombre de faits augmente sans cesse, le temps de calculer une réponse sur ces faits sera de plus en plus long et coûteux.
-
Véracité des faits : Les faits ne doivent jamais être corrompus sans quoi il serait impossible de calculer un état stable du système et nos données ne serviraient plus rien. L’avantage des faits est qu’on ne les change jamais, on se prémunit ainsi des erreurs humaines (ie des algorithmes comportant des bugs). Il ne reste donc plus qu’a se protéger des erreurs machines (coupure électrique, pannes etc..)
Pour résoudre le problème du stockage, il faut mettre en place des solutions de système de fichiers distribués. Il en existe sur le marché, Hadoop par exemple. Afin de garantir la véracité des faits, il nous faut un système qui ne tombe jamais en panne, pour cela nous pouvons nous orienter vers des systèmes redondants telle que mis en oeuvre dans le cloud.
Pour résoudre les problèmes de performance nous pouvons mettre en oeuvre une “lambda architecture”.
Lambda Architecture
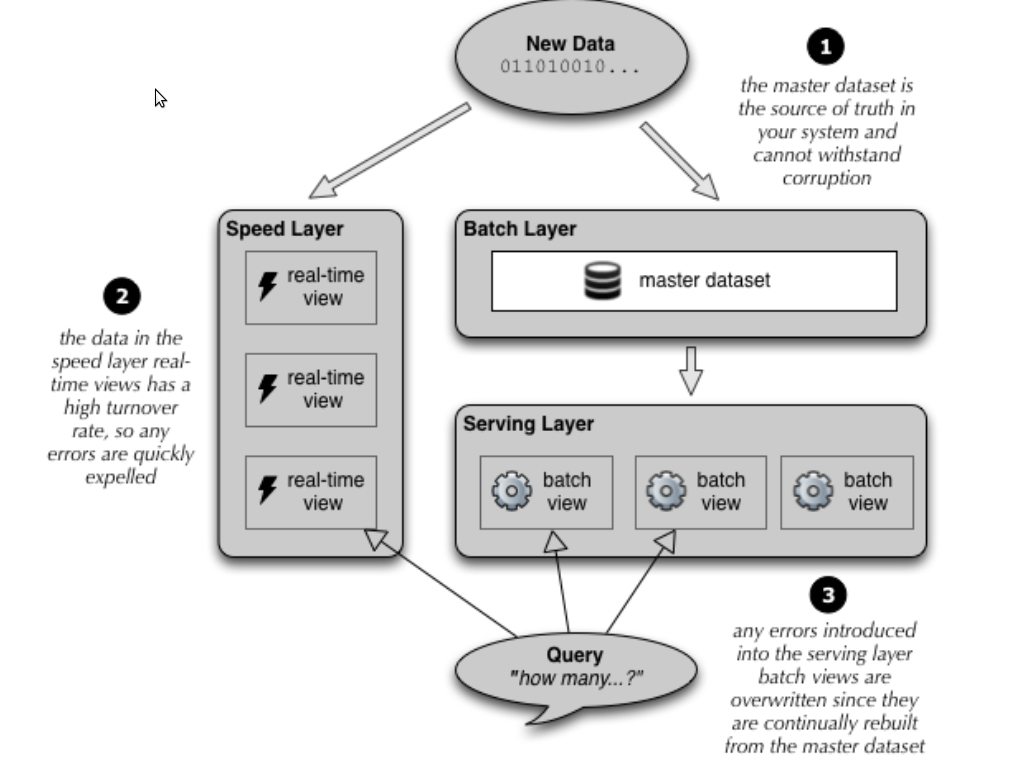
Tiré du livre « BigData » des éditions Manning
Lorsqu’une donnée entre dans le système (une action sur le site par exemple), elle est :
- traitée par les speeds layers afin de recalculer au fil de l’eau les vues « optimisées pour la lecture ». Idéalement on cherchera à atteindre une complexité constante en lecture pour chaque vue quitte à faire un calcul inexacte lorsque cela est acceptable. Comme la vue est déjà précalculé depuis l’état N-1, il est le plus souvent possible de la mettre à jour avec une complexité constante également. On s’est amusé ici avec des bases orienté lecture (SQL, Mongo, Redis etc..) ainsi que des architectures à base de composants et de queues (JMS, Akka etc.)
- stockée en parallèle dans notre base de faits (Batch layer). En mode ‘append only’. Là encore il faut viser une complexité d’écriture constante. On pourra s’amuser à utiliser Cassandra qui à l’avantage de nous permettre de stocker les faits ordonnés, ce qui peut se réveler très utiles pour recalculer nos vues à partir d’un instant T ou tout simplement pour le parcours des données. On pourra également stocker les données dans Hadoop, tout dépendra de la nature de celles-ci et de ce qu’on veut en faire.
Le serving layer permet de calculer les vues à partir de la base de faits. Il a toujours un temps de retard mais garantie des snapshots du système précis. Il suffit pour les speeds layers de rejouer les données entre un snapshot et le présent pour se « mettre à jour ».
Ainsi en cas de bug détecté à la fois sur le speed layer et le batch layer, il suffit livrer le code corriger du speed layer, recalculer depuis la snapshot qui correspond à la mise en prod du bug jusqu’à aujourd’hui avec les servings layers, puis serving ce snapshot au speeds layers qui recalculeront depuis ce snapshot jusqu’au nouveau présent. Il est donc inutile de couper le site pendant 5 jours, le temps de reprendre les données (je dit ça car c’est du vécu).
En résumé
En tant que professionnel, il du plus mauvais effet de devoir dire à un client qu’on a perdu des informations, à cause d’un système basé sur des updates. Une application basique se contente souvent de n’avoir que des speed layers et des vues. Lassé de paraître ridicule quand on nous demande ce qu’il se passe sur notre système, on y ajoute un système de log déstructuré qui est souvent insuffisant.
Aussi, les bugs corrompent les données et il est parfois impossible de les restaurer.
Finalement, mettre une place une architecture orienté data est plus couteuse qu’une application basique mais elle rend obsolète le besoin de logguer et permet de faire infiniement plus de choses, comme la restauration du système lorsqu’un bug a corrompu les vues, et la possibilité d’ajouter des fonctionnalités d’historique qui fonctionneront sur les données du passé.
Pour creuser le sujet, je vous conseille de lire l’excellent livre : Big Data

]]>
Je commence par le CV, j’ai souvent des gens qui ont plus de 15ans d’expériences donc je demande les 2 expériences les plus importantes pour eux et de les détailler (technos, nombre de personne dans l’équipe, challenges techniques/humains).
J’embraye sur des questions basiques sur les tests en fonction du cv du candidat :
- Différence entre JUnit et testNG et pourquoi on préfère l’un à l’autre
- Qu’est ce qu’un mock
- Qu’est ce qu’une Rules JUnit
- Quel est le moyen le plus simple de relancer n fois un test avec testNG ? Et sur plusieurs threads ?
- Quels frameworks de tests connaissez vous ? (culture G)
- Qu’est ce qu’un test paramétré (+ explications de la syntaxe) ?
Quelques basiques questions sur maven :
- Quels sont les différentes scopes ?
- Citer un plugin maven dédié au test ?
- Quelle est la différence entre maven et ant ?
- Comment activer un profile ?
Ensuite je passe sur la concurrence :
- Qu’est ce qu’une race condition ?
- Qu’est ce que volatile ?
- Est ce que ca garantit l’atomicité ?
- Qu’est ce que l’atomicité ?
- Comment marche l’intérieur de la ConcurrentHashMap ?
- Qu’est ce qu’une barrière ?
Culture G :
- Quel est le dernier livre technique que vous ayez lu ?
- Quel est votre livre technique préféré ?
J’aime bien aussi quand le candidat a un compte github.
Vu le poste, on veut des gens qui connaissent un minimum la concurrence (Java concurrency in practice est un très bon livre sur le sujet), un minimum de maven et un bon niveau de test.
Je continue jusqu’à ce que le candidat ne sache plus répondre pour chacun des 3 blocs. J’ai enlevé toutes les questions type SCJP, ca s’apparente trop à du bachotage. J’essaie de garder à peu près les memes questions pour pouvoir différencier les candidats.
Ensuite, on vient d’ajouter le kata sur les chiffres romains qu’on demande de mettre sur github pour voir si la personne sait effectivement coder. La dessus, je n’ai pas encore de retour mais j’espère bien que ca permettra de bien voir si la personne sait mettre en place un minimum de bonnes pratiques.
Et je recherche de nouvelles idées !
Et comment est ce que je sélectionne ?
Il est normal de ne pas tout savoir ! Avant toute chose, on essaie de voir surtout si le candidat réfléchit bien. C’est aussi utile pour moi de voir comment le candidat réagit quand il ne connait pas. Est-ce qu’il pipeaute, qu’il admet, qu’il tente un truc ? C’est surtout vrai pour les questions sur la concurrence et notamment la question sur la concurrent hashmap.
Les seuls points bloquants seraient une lacune complète sur les tests et sur maven. Sur la concurrence, je conseille en entretien de lire Concurrency in Practice. Et pour les lecteurs de ce blog,si vous n’avez qu’un temps réduit, il y a une refcard écrite par un ancien de terracotta sur DZone qui date un peu http://refcardz.dzone.com/refcardz/core-java-concurrency mais qui est claire. Pour postuler pour un job sur un cache distribué, maitriser un peu les concepts de concurrence c’est apprécié.
Merci à tous ceux qui m’ont aidé hier sur twitter !
]]>Arquillian est un outil qui permet de faire des tests d’intégration. Il permet notamment de construire programmatiquement des jar, war et ear très simplement et de déployer ces pseudos-livrables dans un serveur embarqué.
Étant adepte du TDD, quand on me demande de faire un service web, j’aime me mettre à la place du client web et manger du HTTP afin de vérifier le contenu des retours mais aussi les entêtes, les E-Tag, la compression etc… C’est que nous permet de faire Rest-Assured. Nous allons justement voir dans cet article comment tester un service web par la couche HTTP en se servant d’Arquillian pour déployer le service de manière embarqué.
Dans cet exemple, nous utilisons le serveur glassfish embedded. Nous testons un service REST permettant de consulter des logs applicatifs. Ainsi on souhaite vérifier que la requête HTTP : « GET http://localhost:8181/logs?severity=error » retourne bien un code HTTP 200 OK.
Le Test
Voici le code test que nous souhaitons faire :
import org.jboss.arquillian.container.test.api.RunAsClient;
import org.jboss.arquillian.junit.Arquillian;
import com.jayway.restassured.RestAssured;
import com.jayway.restassured.parsing.Parser;
import com.jayway.restassured.specification.ResponseSpecification;
import static com.jayway.restassured.RestAssured.expect;
import static com.jayway.restassured.RestAssured.given;
@RunWith(Arquillian.class)
public class SomeArquillianTest{
@Test
@RunAsClient
public void simpleClientTestExample(@ArquillianResource URL baseURL) throws IOException {
expect().statusCode(200).when().get(baseURL.toString() + "logs?severity=ERROR");
}
}
- @RunWith(Arquillian.class) permet d’utiliser le runner JUnit d’Arquillian.
- @RunAsClient permet de marquer le test comme étant un test de type « Client ».
- @ArquillianResource permet d’injecter l’url de base afin de connaitre l’addresse http de l’application.
Créer l’archive à déployer
Afin qu’Arquillian puisse créer une archive de déployement, il suffit de lui spécifier les composants que nous souhaitons tester (classe annotées @Stateless par exemple.) ainsi que le container / Servlet et le fichier web.xml .
import com.sun.jersey.spi.container.servlet.ServletContainer;
import org.jboss.arquillian.container.test.api.Deployment;
import org.jboss.arquillian.test.api.ArquillianResource;
import org.jboss.shrinkwrap.api.Archive;
import org.jboss.shrinkwrap.api.ArchivePaths;
import org.jboss.shrinkwrap.api.ShrinkWrap;
import org.jboss.shrinkwrap.api.asset.EmptyAsset;
import org.jboss.shrinkwrap.api.spec.WebArchive;
@RunWith(Arquillian.class)
public class simpleClientTestExample {
@Deployment
public static Archive<?> createTestArchive() {
return ShrinkWrap.create(WebArchive.class)
.addPackages(true, Log.class.getPackage(),
LogServiceRest.class.getPackage(),
LogService.class.getPackage())
.addClass(ServletContainer.class)
.setWebXML("WEB-INF/web.xml")
}
Changer le port du serveur embarqué
- Le port par défault pour glassfish-embedded est : 8181 (https://docs.jboss.org/author/display/ARQ/GlassFish+3.1+-+Embedded)
- Il est possible de surcharger cette propriété, comme toutes les autres d’ailleurs, dans le fichier arquillian.xml :
<arquillian xmlns="http://jboss.org/schema/arquillian"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://jboss.org/schema/arquillian http://jboss.org/schema/arquillian/arquillian_1_0.xsd">
<engine>
<property name="deploymentExportPath">target/arquillian</property>
</engine>
<container default="true" qualifier="glassfish">
<configuration><property name="bindHttpPort">8181</property></configuration>
</container>
</arquillian>
La pomme
Voici un extrait de ma pomme, à adapter selon votre situation…
<dependencies>
<dependency>
<groupId>org.glassfish.main.extras</groupId>
<artifactId>glassfish-embedded-all</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-api</artifactId>
<scope>provided</scope>
</dependency>
<!-- Librairies for test -->
<dependency>
<groupId>org.hamcrest</groupId>
<artifactId>hamcrest-library</artifactId>
<version>1.3</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<dependency>
<groupId>org.jboss.arquillian.junit</groupId>
<artifactId>arquillian-junit-container</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.jayway.restassured</groupId>
<artifactId>rest-assured</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>2.2</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>2.1</version>
<executions>
<execution>
<phase>validate</phase>
<goals>
<goal>copy</goal>
</goals>
<configuration>
<outputDirectory>${endorsed.dir}</outputDirectory>
<silent>true</silent>
<artifactItems>
<artifactItem>
<groupId>javax</groupId>
<artifactId>javaee-endorsed-api</artifactId>
<version>6.0</version>
<type>jar</type>
</artifactItem>
</artifactItems>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
Et voilà ! Plutôt simple non ?
]]>- les annotations de mapping
- les apis
- la sémantique (cascade …)
- et le JP-QL
Plus d’infos sur le blog d’Emmanuel Bernard
Alors qu’au début, il n’y avait que Infinispan, on peut désormais y trouver MongoDB et Ehcache. D’autres types viendront surement. Ici, Ehcache est utilisé non pas comme un cache mais comme un datastore noSQL clé/valeur.
Configuration
Pour effectuer des insertions dans Ehcache via OGM, c’est vraiment simple. Après avoir ajouter la dépendance hibernate-ogm-ehcache à votre POM, il faut ensuite faut un fichier persistence.xml.
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="ogm-ehcache" transaction-type="JTA">
<provider>org.hibernate.ogm.jpa.HibernateOgmPersistence</provider>
<properties>
<property name="hibernate.ogm.datastore.provider"
value="ehcache"/>
<property name="hibernate.transaction.jta.platform"
value="org.hibernate.service.jta.platform.internal.JBossStandAloneJtaPlatform"/>
</properties>
</persistence-unit>
</persistence>
Note : Actuellement, les transactions, qui sont gérées de manière native par Ehcache, ne fonctionnent pas avec OGM.
Il faut ensuite instancier l’entityManager.
Configuration cfg = new OgmConfiguration().
setProperty("hibernate.ogm.datastore.provider", "ehcache").
addAnnotatedClass(Appli.class).addAnnotatedClass(Platform.class);
TransactionManager tm = getTransactionManager();
EntityManagerFactory emf = Persistence.createEntityManagerFactory("ogm-ehcache");
try {
EntityManager em = emf.createEntityManager();
Many-to-One
Le modèle est le suivant : 2 classes, Appli et Perform.
@Entity @Indexed
public class Appli {
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator = "appli")
@TableGenerator(
name = "appli",
table = "sequences",
pkColumnName = "key",
pkColumnValue = "apply",
valueColumnName = "seed"
)
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
private Long id;
public String getName() { return name; }
public void setName(String name) { this.name = name; }
private String name;
@ManyToOne
@IndexedEmbedded
public Platform getPlatform() { return platform; }
public void setPlatform(Platform platform) { this.platform = platform; }
private Platform platform;
}
@Entity @Indexed
public class Platform {
@Id
@GeneratedValue(generator = "uuid")
@GenericGenerator(name="uuid", strategy="uuid2")
public String getId() { return id; }
public void setId(String id) { this.id = id; }
private String id;
@Field
public String getName() { return name; }
public void setName(String name) { this.name = name; }
private String name;
}
On crée ensuite un objet learnAnimals de type Appli qui a pour plateforme itunes.
Platform itunes = new Platform();
itunes.setName("iTunes");
Appli learnAnimals = = new Appli();
learnAnimals.setName("J apprends les animaux" + i);
learnAnimals.setPlatform(itunes);
On persiste de la meme manière qu’avec hibernate.
tm.begin(); em.persist(learnAnimals); Long leanAnimalsId = learnAnimals.getId(); em.flush(); em.close(); tm.commit();
Et voilà, l’objet learnAnimals est persisté. Mais à la différence d’une persistance classique avec Ehcache, qui fonctionne par sérialisation/déserialisation des objets, le modèle est déshydraté.
tl;dr
Pour une entité, elle est donc stockée dans une store ENTITIES avec le modèle clé/valeurs suivant :
Clé
Chaque clé est de type EntityKey, classe qui contient entre autre :
private final String table; private String[] columnNames; private Object[] columnValues;
On aura par exemple : {table=’Appli’,columnNames=[‘id’],columValues=[‘1’]} pour l’appli qui a pour identifiant la valeur 1.
Pour la valeur, elle est construite sous la forme d’une map.
Ainsi pour un object Appli qui contient une Plateforme, la map aura cette forme :
Clé | Valeur id | 1 name | monAppli platform_id | 65d2183a-3a73-4079-83fb-57f9072e0915
A l’insertion c’est un peu plus compliqué. On passera par des objets transitoires, des aggregats nommé TupleOperation qui contiennent le nom de la colonne, sa valeur et son type TupleOperationType, celui-ci pouvant prendre 3 valeurs, PUT, PUT_NULL et REMOVE.
On a donc en fait :
Key | Value
id | {columnName='id',columnValue='1'.columnType=TupleOperationType.PUT}
name | {columnName='name',columnValue='monAppli'.columnType=TupleOperationType.PUT}
platform_id | {columnName='platform_id',columnValue='2886a75c-11ae-4f3d-a132-8d58010382b3'.columnType=TupleOperationType.PUT}
La valeur PUT indiquera qu’il faut faire un
map.put( action.getColumn(), action.getValue() );
C’est à dire pour le premier exemple :
map.put('id',1)
Un remove aurait entrainé une suppression de la paire clé/valeur. Un PUT_NULL fait la même chose qu’un PUT.
On a donc bien inséré en base :
Clé | Valeur id | 1 name | monAppli platform_id | 65d2183a-3a73-4079-83fb-57f9072e0915
On aura une entrée similaire dans le meme cache ENTITIES pour les objets de types Platform. Pour résumer, on a donc :
Map<EntityKey,Map<String,Object>>
La deuxième store est la store ASSOCIATION. Elle n’est utile que dans les relations plus complexes.On y reviendra par la suite. Dans ce cas, elle reste vide.
La troisième store est la store des IDENTIFIERS, qui stocke les informations relatives aux séquences, notamment toutes celles qui permettent de gérer de manière automatique les identifiants.
Many-to-Many
On définit maintenant une application comme pouvant être associée à N plateforme. Le modèle de Platform ne change pas, celui d’Appli légerement.
@Entity @Indexed
public class AppliManyToMany {
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator = "appli")
@TableGenerator(
name = "appli",
table = "sequences",
pkColumnName = "key",
pkColumnValue = "apply",
valueColumnName = "seed"
)
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
private Long id;
public String getName() { return name; }
public void setName(String name) { this.name = name; }
private String name;
@ManyToMany
@IndexedEmbedded
public List getPlatforms() { return platforms; }
public void setPlatforms(List platforms) { this.platforms = platforms; }
private List platforms=null;
}
En ce qui concerne la table ENTITY, elle est un peu modifié.
La clé reste identique, par contre l’enregistrement ayant pour clé platform_id n’existe plus. On a uniquement :
Clé | Valeur id | 1 name | monAppli
L’association est désormais portée par un enregistrement dans la table ASSOCIATION.
La clé, de type AssociationKey, similaire à une EntityKey, représentant l’id 5 :
{table=’AppliManyToMany_Platform’, columnNames=[AppliManyToMany_id], columnValues=[5]}
La valeur est toujours une Map :
Clé (de type RowKey) : {table=’AppliManyToMany_Platform’, columnNames=[AppliManyToMany_id, platforms_id], columnValues=[5, 6301e8be-307f-4884-b3a1-5ec0dad7c3e5]}
Valeur (sous la forme d’une Map): {AppliManyToMany_id=5, platforms_id=2886a75c-11ae-4f3d-a132-8d58010382b3}}
On a donc une structure de la forme :
Map<AssociationKey,Map<RowKey,Map<String,Object>>>
Pour cet exemple, il n’y a qu’une seule plateforme, celle qui a l’id 6301e8be-307f-4884-b3a1-5ec0dad7c3e5, ainsi, on a donc un unique enregistrement dans la map.
Si on prends un exemple où une application est associée à deux personnes (appli avec id= 6):
On pourrait avoir comme clé principale :
table=’AppliManyToMany_Platform’, columnNames=’AppliManyToMany_id’, columnValues=’6′
Puis comme value les couples clés/valeurs suivants :
RowKey 1 :
Clé (RowKey) : {table=’AppliManyToMany_Platform’, columnNames=[AppliManyToMany_id, platforms_id], columnValues=[6, b705d241-b6dd-4a81-9fb2-2f9f732530d7]}
Valeur associée (sous forme de map): {AppliManyToMany_id=6, platforms_id=b705d241-b6dd-4a81-9fb2-2f9f732530d7}
RowKey 2 :
Clé (RowKey) : {table=’AppliManyToMany_Platform’, columnNames=[AppliManyToMany_id, platforms_id], columnValues=[6, 2886a75c-11ae-4f3d-a132-8d58010382b3]}
Valeur associée (sous forme de map): {AppliManyToMany_id=6, platforms_id=2886a75c-11ae-4f3d-a132-8d58010382b3}
On a donc bien pour l’application 6 deux plateformes, la plateforme b705d241-b6dd-4a81-9fb2-2f9f732530d7 et la 2886a75c-11ae-4f3d-a132-8d58010382b3 . Le framework se servira des identifiants dans un deuxième temps pour retrouver dans la table ENTITIES les plateformes correspondantes et les ‘ajoutera’ dans la liste des plateformes de l’application id=6. Pour avoir une idée encore plus concrète, il y a des schémas dans la documentation d’OGM.
A venir : Hibernate Search, Lucene et autres recherches avec Hibernate OGM.
]]> Et oui, bizarre de parler de ça dans un blog qui fait l’apologie du freelancing, mais ceux qui me suivent savent sans doute déjà que je ne suis plus tout à fait seul…
Et oui, bizarre de parler de ça dans un blog qui fait l’apologie du freelancing, mais ceux qui me suivent savent sans doute déjà que je ne suis plus tout à fait seul…
Je suis associé depuis le début de cette année à 4 compagnons d’aventure :
- Hugo Lassiège ( hakanai.free.fr )
- Olivier Girardot ( http://www.readtfb.net/ )
- Florent Biville ( http://florent.biville.net/ )
- Jonathan Winandy ( http://hbrain.net/)
Liberté ++
Et oui, quand on est freelance, on est un peu plus libre qu’un salarié, mais que faire de cette liberté seul ? C’est incroyable ce qu’on peut faire quand on est plusieurs, ne serait que 5 pauvres petits développeurs. Depuis la création de Lateral-Thoughts, il y a quelques mois seulement :
- Nous sommes devenus organisme de Formation (certains freelances le sont aussi mais beaucoup se contentent de se faire porter pour donner des formations)
- Nous avons noué un partenariat avec un éditeur de base de données NoSQL (quel freelance peut faire ça ?)
- Nous nous sommes passé d’intermédiaires ! Certains freelances y arrivent aussi, mais là, c’est juste plus simple.au
Finalement se regrouper dans une structure de type NoSSII(a) telle que LT c’est donner un sens à sa liberté, ou plus généralement, découvrir ce que devrait être une société composée de professionnels de l’informatique.
Tout n’est pas rose
Et oui, ce serait trop facile sinon. LT est une société qui innove dans son organisation en copiant honteusement le principe agile d’auto-organisation. LT est clairement auto-organisée. Chaque membre est libre de prendre le lead sur un sujet qui l’intéresse. Il est parfois rejoint par d’autres, et à chaque fois soutenu par tout le groupe. Mais que faire lorsque personne ne souhaite prendre le lead sur un sujet pourtant important ? Ou que faire si le sujet est trop vaste pour qu’une seule personne s’en occupe alors qu’il faudrait être plusieurs ? L’exemple le plus flagrant est notre site Internet, quelques peu délaissé, faute de temps et de motivation.
Mais ce n’est pas grave, en agrandissant notre cercle, nous trouverons sans nul doute les bras qui nous manquent pour faire aussi bien que nos SSII favorites et bien aimées (Xebia, So@t, Zenika, Valtech, pour ne citer qu’elles). Traduction : nous sommes ouverts aux candidatures.
La cerise sur le gâteau
C’est cool, quand j’étais freelance il m’est arrivé de financer un hands-on ou 2 organisés par Mathilde et les Duchess (Location de la salle ou repas). Mais aurai-je pu me permettre de payer une semaine de startup-week-retreat à 7 développeurs passionnés ? Et non, trop cher pour mon petit porte-monnaie. En revanche, à 5 on peut aisément le faire, et c’est ce que nous avons fait !
Dès demain, nous partons à Guérande, pour 8 jours de code intensif avec 4 membres de LT et 3 potes : @nivdul @piwai et @ubourdon . Au programme, du fun : Scala, Android, MongoDB (rien n’est fixé à l’avance, on décidera sur place ce qu’on fait, à la manière d’un hackergarten). Mais aussi de la souffrance : tennis, piscine, jogging et bodyboard … L’idée c’est vraiment de progresser tous ensemble dans la joie et la bonne humeur ^^
On devrait renouveler l’expérience cet hiver ! Si l’expérience vous intéresse, suivez nos blogs ou nos twitter, ça devrait blogguer pendant la semaine
Trève de blabla, passons au code.
Premièrement, ajouter un champ input acceptant l’ajout de plusieurs fichiers :
<input id="files" multiple="multiple" name="file[]" type="file">
Ensuite, uploadons les fichiers en utilisant les « FormData » d’HTML5 :
var upload = function (file) {
var data = new FormData();
data.append('name', file.name);
data.append('file', file);
$.ajax({
url:'/photo',
data:data,
cache:false,
contentType:false,
processData:false,
type:'POST'
}).error(function () {
alert("unable to upload " + file.name);
})
.done(function (data, status) {
doSomethingUseful(data);
});
};
function multiUpload(files) {
for (var i = 0; i < files.length; i++) {
// Only upload images
if (/image/.test(files[i].type)) {
upload(files[i]);
}
}
}
$(document).ready(function () {
$("#files").change(function (e) {
multiUpload(e.target.files);
})
});
Coté serveur, avec Jersey, il faut inclure le module « multipart » :
<dependency>
<groupId>com.sun.jersey.contribs</groupId>
<artifactId>jersey-multipart</artifactId>
<version>1.13</version>
</dependency>
Ensuite le code est plutôt simple :
import javax.inject.Inject;
import javax.ws.rs.*;
import javax.ws.rs.core.MediaType;
import com.sun.jersey.core.header.FormDataContentDisposition;
import com.sun.jersey.multipart.FormDataParam;
import java.io.IOException;
import org.apache.log4j.Logger;
import org.springframework.stereotype.Controller;
@Controller
@Path("/photo")
public class PhotoResource extends AbstractResource {
private static final Logger LOG = Logger.getLogger(PhotoResource.class);
@Inject
private FileRepository fileRepository;
@GET
@Produces("image/png")
@Path("/{photoId}")
public byte[] photo(@PathParam("photoId") String photoId) {
try {
return fileRepository.get(photoId);
} catch (IOException e) {
LOG.warn("When get photo id : " + photoId, e);
throw ResourceException.notFound();
}
}
@POST
@Consumes(MediaType.MULTIPART_FORM_DATA)
@Produces(MediaType.TEXT_PLAIN)
public String addPhoto(@FormDataParam("file") byte[] photo,
@FormDataParam("file") FormDataContentDisposition fileDetail) {
String photoId = null;
try {
photoId = fileRepository.save(photo);
} catch (IOException e) {
LOG.error("unable to add photo", e);
throw ResourceException.error(e);
}
return photoId;
}
}
Et pour s’amuser, stockons les fichiers dans Mongodb grace à GridFS :
import javax.annotation.PostConstruct;
import javax.inject.Inject;
import com.mongodb.gridfs.GridFS;
import com.mongodb.gridfs.GridFSInputFile;
import java.io.IOException;
import org.apache.commons.io.IOUtils;
import org.bson.types.ObjectId;
import org.jongo.Jongo;
import org.springframework.stereotype.Repository;
@Repository
public class FileRepository {
private Jongo jongo;
private GridFS files;
@Inject
public FileRepository(Jongo jongo) {
this.jongo = jongo;
}
@PostConstruct
public void afterPropertiesSet() throws Exception {
files = new GridFS(jongo.getDatabase());
}
/**
* Save a file and return the corresponding id
*/
public String save(byte[] file) {
GridFSInputFile savedFile = this.files.createFile(file);
savedFile.save();
return savedFile.getId().toString();
}
/**
Return the file
*/
public byte[] get(String fileId) throws IOException {
return IOUtils.toByteArray(files.findOne(new ObjectId(fileId)).getInputStream());
}
}
}
Et si vous voulez faire du drag and drop, il suffit d’inclure ce plugin jQuery : drop.js et de faire comme ceci :
$(document).ready(function () {
$('body').dropArea();
$('body').bind('drop', function (e) {
e.preventDefault();
e = e.originalEvent;
multiUpload(e.dataTransfer.files);
});
});
Sources :
]]>Java Barcamp 8
Le Java Barcamp 8 aura lieu le jeudi 5 juillet. Nous pourrons partager ensemble au cours de discussions libres nos idées et nos dernières nouvelles autour de la plate-forme Java, ce sera un format pique nique alors chacun vient avec une bouteille, de quoi grignoter et vos « accessoires », verres, couverts, tire-bouchons, etc…). Plus d’infos : http://barcamp.org/w/page/54826845/JavaCampParis8
Jam de Code
La semaine suivante, le Jam de Code de la SSII Arolla aura lieu le 12 juillet ! Le principe est simple: venez coder avec d’autres passionnés dans une ambiance détendue ! Plus d’infos : http://www.arolla.fr/evenements-2/jams-de-code/
Hackergarten
Le vendredi 20 juillet, de 19h à 23h, aura lieu un hackergarten dans les locaux de Zenika. C’est le rendez-vous des gens qui veulent participer aux projets open source. L’idée c’est, dans un format de 3h, de contribuer un logiciel, un fix, un feature, une documentation dont d’autres pourraient avoir l’usage. Il s’articule autour de commiters actifs pour mentorer les hackers qui participent à l’évènement. Plus d’infos : http://www.eventbrite.com/event/2737661419
Cassandra Paris Meetup
Le premier Cassandra Paris meetup aura lieu le mercredi 25 juillet de 19h à 22h30 ! Il s’adresse à tous, novices et confirmés ! Il y aura 2 présentations, une intro à Cassandra et une étude d’un cas réel à paper.li . Plus d’infos : http://cassandra-paris.eventbrite.fr/
Si vous connaissez d’autres événements, faites nous en part, nous les rajouterons !

Qu’est ce qu’un Bar Camp ?
![]() Wikipédia :
Wikipédia :
Un BarCamp est une rencontre d’un week-end, une non-conférence ouverte qui prend la forme d’ateliers-événements participatifs où le contenu est fourni par les participants qui doivent tous, à un titre ou à un autre, apporter quelque chose au Barcamp.
C’est le principe pas de spectateur, tous participants. L’événement met l’accent sur les toutes dernières innovations en matière d’applications Internet, de logiciels libres et de réseaux sociaux.
Si vous souhaitez venir, il suffit de s’inscrire ici : http://barcamp.org/w/page/54826845/JavaCampParis
Il y a également un plan précis pour s’y retrouver !
Enfin presque, l’idée est d’installer un server X virtuel : Xvfb
% sudo apt-get install xvfb
Ensuite lancer le server X virtuel :
% Xvfb :1 &
:1 permet de spécifier le nom du « display »
Et pour finir, le build selenium ( ou n’importe quelle commande ayant besoin d’un « display »)
DISPLAY=:1 mvn clean install]]>
 Redis est la base de données NoSql que je préfère. Le concept est ultra-simple et j’aime la simplicité. Il faut voir Redis comme une grosse Map<K,V>. Avec la possibilité de faire des requêtes sur les clés.
Redis est la base de données NoSql que je préfère. Le concept est ultra-simple et j’aime la simplicité. Il faut voir Redis comme une grosse Map<K,V>. Avec la possibilité de faire des requêtes sur les clés.
Du coup la documentation de Redis est simple. Un autre truc que j’aime c’est qu’elle spécifie la complexité de chaque opération, ce qui permet au développeur de vérifier à chaque fois que la commande qu’il s’apprête à utiliser n’est pas trop gourmande. De plus, il n’a pas le risque d’oublier de mettre un index sur un champ (combien de fois cela arrive en SQL ou avec MongoDb ! ) car toutes les clés sont par définition « indexées » dans une (Hash) Map.
Simple et (donc ?) performant. Redis est sans doute ce qu’il y a de plus performant en terme de base de données. Nous avons donc intérêt à nous y intéresser avant de chercher des solutions plus complètes et donc plus complexes et moins performantes.
Sauf que, Redis ne stocke que des chaînes de caractères. Comment faire pour stocker nos objets métiers complexes ?
On pourrait simplement utiliser une base de données SQL pour stocker notre modèle et utiliser un ORM pour que ce soit « simple ». Ensuite dans Redis on ne stockerai que la dé-normalisation de certaines requêtes : 3 meilleurs clients => { 1 => id:130 ; 2 => id:345 ; 3 => id:456 } Ainsi la requête pour récupérer les identifiants des trois meilleurs clients se fera en temps constant O(1) puis la requête pour récupérer les données des trois clients dans la base SQL se fera également en temps constant, car les clés primaires sont indexées dans les bases SQL.
Mais il faut avouer que c’est embêtant de devoir gérer deux bases de données, surtout quand on pourrait simplement sérialiser les objets directement dans Redis.
Stocker les objets Java dans Redis grâce à Jackson
Dans notre exemple, le besoin est de pouvoir insérer des liens dans des listes et de pouvoir récupérer en temps constant tous les liens d’une liste donnée.
Jackson est un sérialiseur Objet -> JSON. Ce qui est parfait pour pouvoir lire facilement les objets sérialisé où pour pouvoir les utiliser directement en JavaScript, sans passer par une dé-sérialisation.
On va utiliser JAX-B pour annoter nos objets Java, par exemple :
@XmlRootElement(name = "links")
@XmlAccessorType(FIELD)
public class BannerLink {
private String label;
private String url;
public BannerLink(String label, String url) {
this.label = label;
this.url = url;
}
public String getLabel() {
return label;
}
public String getUrl() {
return url;
}
protected BannerLink(){}
}
Notez que Jackson sait aussi sérialiser des POJOs (sans JAX-B mais avec Setter)
Ensuite il suffit de sérialiser l’objet avec Jackson pour l’insérer dans une liste Redis.
AnnotationIntrospector introspector = new JaxbAnnotationIntrospector();
mapper.getDeserializationConfig().setAnnotationIntrospector(introspector);
mapper.getSerializationConfig().setAnnotationIntrospector(introspector);
jedis.rpush("listKey", mapper.writeValueAsString(link));
Pour la lecture, il suffit de dé-sérialiser les objets de la liste.
mapStringsToLinks(jedis.lrange(key, 0, jedis.llen(key)));
private List mapStringsToLinks(List jedisResult) {
return Lists.transform(jedisResult, toBannerLink());
}
private Function<String, BannerLink> toBannerLink() {
return new Function<String, BannerLink>() {
@Override
public BannerLink apply(@Nullable String link) {
return mapper.readValue(link, BannerLink.class);
}
};
}
Je ne sais pas vous, mais moi je trouve ça vraiment plus simple de persister directement et simplement les instances d’objets, telle quelle, sans se prendre la tête avec du mapping, jointure ou autre joyeuseté.
Performances
Je n’ai pas fait le test avec une base SQL et un ORM de type Hibernate mais n’hésitez pas à forker le code et à le faire, ça m’intéresse.

Aucun tuning n’a été fait sur les bases de données. Mongo est bien meilleur en écriture et peut être encore meilleur, car il ne garantie pas que les données sont effectivement écrites sur le disque, j’avoue ne pas avoir cherché à optimiser Redis pour l’écriture, j’ai gardé la configuration par défaut.
En revanche, Redis est bien meilleur en lecture, malgré le surplus de traitements dû à la désérialisation Jackson. Et c’est ce qu’on cherche dans notre cas d’usage, nos listes de liens vont être lus beaucoup plus souvent que modifiées. Et pour ceux qui se poseraient la question, oui j’ai bien créé les indexes dans Mongo.
Ce qu’il faut retenir, c’est que dans bien des cas, une base de données document ou SQL n’est pas forcément obligatoire et qu’il vaut mieux démarrer simple et (très) efficace, quitte à changer par la suite…
Un peu de lecture si vous souhaitez en savoir plus sur Redis : Redis: the Definitive Guide: Data Modeling, Caching, and Messaging
@Configuration
public class RequestConfiguration {
@Value(value = "${repository?InMemoryRepository}")
private String repository;
}
Pour ce faire, il faut configurer le property placeholder de Spring pour :
- Ignorer les @Value vide
- remplacer le séparateur par défaut (« : ») par « ? » qui est plus parlant.
<bean id="placeholderConfig">
<property name="locations">
<list>
<value>classpath:conf.properties</value>
</list>
</property>
<property name="ignoreResourceNotFound" value="true"/>
<property name="ignoreUnresolvablePlaceholders" value="true" />
<property name="valueSeparator" value="?" />
</bean>
Et voilà !
Maintenant il faut faire attention car Spring va ignorer toutes les properties null ce qui pourra provoquer des NullPointerException à l’exécution plutôt que des erreurs de configuration au démarrage de l’application…
]]>Avec Jersey, l’implémentation de référence de JAX-RS (JSR311) pas de prise de tête, tout est générés automatiquement.
Il suffit de faire deux choses :
- Créer une classe de type « com.sun.jersey.api.wadl.config.WadlGeneratorConfig »
- Passer cette classe en paramètre d’initialisation de votre servlet
public class SchemaGenConfig extends WadlGeneratorConfig {
@Override
public List configure() {
return generator( WadlGeneratorJAXBGrammarGenerator.class).descriptions();
}
}
<servlet>
<servlet-name>
banner
</servlet-name>
<servlet-class>
com.lateralthoughts.commons.web.LateralCommonsServlet
</servlet-class>
<init-param>
<param-name>
com.sun.jersey.config.property.WadlGeneratorConfig
</param-name>
<param-value>
com.lateralthoughts.commons.web.wadl.SchemaGenConfig
</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
Le WADL est maintenant généré et accessible à cette adresse : http://localhost:port/maservlet/application.wadl
Pour aller plus loin, le wiki d’Oracle : https://wikis.oracle.com/display/Jersey/WADL
Merci à Aurélien Thieriot pour l’astuce 
Devoxx France en deux mots : C’est la plus grande et la plus intéressante des conférences pour les développeurs Java en France.
Pour moi, ce fut une expérience formidable. En plus d’avoir appris quelques trucs, ce qui m’a fait le plus plaisir c’est d’avoir été conforté sur pas mal de choix que j’ai pu faire ou que je comptais appliquer prochainement. Hormis l’absence de desserts sucrés et le nombre limité de boissons, l’organisation fut parfaite. Un grand bravo aux organisateurs !
J’ai choisi d’illustrer ces trois jours de conférences par une série d’articles qui racontent ce que pourrait être une success story pour un développeur Java ayant eu une « idée » :
Pour la petite histoire, je craignais au début que limiter à 25% le nombre de speakers anglophones allait mathématiquement faire baisser le niveau des speakers. Cela c’est avéré faux, le niveau des Français fut excellent, même meilleurs que les anglophones que j’ai pu voir. Bravo à tous et vive la France !
Quant à moi (beaucoup m’ont posé la question), si je n’ai rien présenté et que je n’ai pas non plus voulu participer à la préparation de cette première de Devoxx France bien que je sois un Geek Passionné avec plein de choses à raconter, c’est que j’ai déjà beaucoup de projets en cours et je pense qu’il est important de garder un certain équilibre entre vie professionnelle, loisirs, famille et amis afin de ne pas finir en « burnout » (En passant j’ai bien rigolé en lisant http://501manifesto.org/ ).
Je remercie ma société de m’avoir payé la conférence ainsi que l’hôtel au Marriott (4 étoiles c’est la classe !). Et si vous n’êtes pas encore Freelance ou que vous ne faites pas partie d’une société qui vous laisse gérer votre budget tel que Lateral Thoughts, il est peut être temps d’y réfléchir…
A l’année prochaine à Devoxx !
]]>
Web Oriented Architecture
Avant d’être Startupeur, Gérard était architecte urbaniste respecté et vénéré. Mais trop souvent, il a essayé de plier le web pour faire des applications dites « Stateful » où l’état du client est conservé côté serveur via les sessions. Ce qui amène pas mal de problèmes, en terme de performance bien sûr, car il est du coup difficile d’avoir un cache efficace, mais aussi des problèmes de développement, qui n’a jamais galéré à gérer le bouton « back » et à devoir mettre un bouton « back » spécifique dans son application alors que le navigateur lui-même en possède déjà un ?
La présentation de Habib, qui s’approche de la keynote a hypnotisé le public (et Gérard) en cassant les architectures dites « stateful » et antiweb, celle de Sadek et Guillaume montre que Play! pousse le développeur à embrasser le Web plutôt qu’à lutter contre lui.
Mais au fait c’est quoi une architecture Web ?
- Ressource based : Utilisation des URI et des mediatypes pour identifier et exprimer les « ressources » fournies par l’application
- Stateless : L’état de la conversation est gérée côté client, dans le browser. Le client change l’état de l’application via des commandes au serveur (verbes http PUT, POST et DELETE)
- HTTP powered : Utilisation du protocole HTTP et de ses verbes à bon escient : PUT, POST, DELETE, GET. Une application qui embrasse le web est une application qui ne fait que du CRUD.
WAT ? Mais comment va faire Gérard pour ne faire que du CRUD ? Son application fait des vrais trucs de barbus.
En fait c’est super simple, lorsque vous avez de faire un truc « compliqué » (qui n’est pas CRUD), comme par exemple, déplacer une somme d’argent d’un compte A (ressource) à un compte B (autre ressource) vous n’allez, côté client ni demander de modifier le compte A, ni demander de modifier le compte B, mais ajouter une ressource à votre système (via un PUT) et ça, ben c’est du CRUD. Cette commande déclenchera l’exécution de notre traitement métier « complexe » de manière « Atomic » et « Asynchrone » (Toi qui es perspicace tu auras reconnu l’objet bancaire Transaction )
Ceci permet d’avoir entre autre une interface réactive, car l’envoie d’une commande dans une queue est d’une complexité constante.
Ha oui mais du coup, quand on va requêter pour savoir combien il y a sur le compte B il va falloir parcourir toutes les transactions ! (Gérard est fier de sa perspicacité)
Biensûr que non !! La solution est dans le chapitre en dessous avec CQRS, on va séparer le modèle métier d’écriture et le modèle métier de lecture et pré-calculer, dé-normaliser pour être efficace autant en écriture qu’en lecture.
Pour aller plus loin : Implementing REST
CQRS
Le lien fort entre CQRS et la WOA, c’est le CRUD, une architecture CQRS est une architecture à base de commande, comme en WOA, l’idée est de créer des commandes plutôt que de modifier plusieurs entités du modèle. Cela revient donc à faire du CRUD, comme en WOA.

Une architecture CQRS (Command Query Responsabilty Segragation) sépare le modèle d’écriture du modèle de lecture ce qui va permettre :
- De ne pas fetcher d’informations inutiles (On n’a pas besoin du nom du client B pour calculer le solde du client A …) Qui n’a jamais du fetcher des informations inutiles parce que le modèle est unique pour toute l’application ?
- De pré-calculer de manière asynchrone toutes les opérations fortement demandées pour s’approcher d’une complexité constante ( ou linéaire, mais sur un nombre réduit d’éléments).
Bien, se dit Gérard, mais si je suis asynchrone, je ne vais pas voir tout de suite le résultat de ma transaction sur mon compte ! C’est vrai. Mais ce n’est pas grave il faut être « relax », Habid appelle ça la « relaxation temporelle ».
Pour aller plus loin :
Le mot de la fin
Maintenant qu’on ne fait que du CRUD, du Stateless et de l’asynchrone, cela permet de découper facilement nos applications en plusieurs petites applications ou API qui ne traitent que d’une seule problématique, réduisant encore la complexité du système d’information. Les applications web « finales » agrègent ensuite ces API pour présenter quelque chose de « complet » à l’utilisateur final. Évidement ces APIs simples et « unitaires » sont réutilisables par autant d’applicatifs finaux que nécessaires, permettant ainsi une ré-utilisatibilité et une interopérabilité maximale.
Appelez ça comme vous voulez, WOA, REST, CQRS, HTTP, Web. L’avenir est dans la simplicité du CRUD, l’asynchrone et le Stateless. C’est aussi l’avis de Gérard. Est-ce le vôtre ?
]]>
Yeah ! Maintenant que Gérard a son business plan qui roule, qu’il a mis en ligne un premier prototype et que les premiers clients commencent à taper au portillon, il est temps de passer à la vitesse supérieure : Créer sa société.
A Devoxx un quickie à particulièrement attiré mon attention : Celui de Andrew Spencer sur son idée de faire une SSII Coopérative. Ce qui est marrant c’est que c’est ce que nous avons fait depuis quelques mois en créant Lateral-Thoughts.
Pourquoi une SSII coopérative ?
Appliquons le « Lean Canvas » et répondons à quelques questions :
- Problem: En SSII il n’y a pas d’argent, pas de fun et pas de liberté, l’innovation n’est pas encouragée.
- Solution: Faisons une SSII qui donne de l’argent (tous actionnaires) du timeoff pour le fun et l’innovation et de la liberté d’action (management plat).
- Key metrics : Salaires moyen (Argent), Satisfaction des membres (Fun et Liberté)
- Uniq Value Proposition : Une bande de développeurs passionnés et auto-organisés qui s’éclatent à faire en codant et en apprenant ensemble.
- Unfair advantage: On s’en fout, copiez nous, ça nous fera plaisir. D’un point de vue business : Nos réseaux, notre toile « unique »
- Channels: Les réseaux de nos membres, leur rayonnance. Ce blog et d’autres ^^
- Customer segments: Les PME, grands comptes et startups.
- Cost Structure: Quasiment rien, un comptable à 1000€ / an. Pas de locaux. Pas de commerciaux. Pas de managers. Pas de boss.
- Revenue Streams: Prestations, Formations, Editions de solutions logicielles.
Il s’agit du canvas pour Lateral Thoughts mais vous pouvez tout à fait imaginer votre propre SSII coopérative pour répondre à une autre problématique. L’exemple du réseau libre-entreprise en est un autre.
Et pour ma startup ?
Les startupeurs sont des gens innovants. Le problème c’est qu’une fois que le produit est devenu « Legacy » où passe l’innovation ? Généralement on revend la structure et on part créer autre chose. Sauf qu’il n’est pas aisé de réussir à chaque fois, surtout lorsqu’on a qu’un seul cerveau. Pourquoi ne pas mettre en place dès le départ dans sa société une organisation qui permettra à l’innovation d’émerger et ce, de manière durable ? Certains l’ont très bien réussi, je pense à W.L. Gore, Whole Foods ou Google. Il suffit de copier, tous leurs secret sont expliqués dans ce livre : The Future of Management
La clé du management du futur et de passer par des sociétés coopératives, le modèle le plus connu est celui de la sociocratie que je résume en quelques points ici :
- Une personne = une voix
- Transparence totale (même et surtout du compte bancaire)
- Décision prise par consensus (tout le monde, à défaut d’être d’accord doit consentir pour qu’une décision soit prise)
Ce type de société à un coût, car une décision prise par consensus prend du temps alors qu’en société standard, le patron prend les décisions le matin seul dans sa douche. Mais le jeu en vaut la chandelle. Les membre d’une telle société donnent le meilleur d’eux-mêmes, ils se sentent investis, ils se sentent d’une même famille avec un but commun, mais aussi des objectifs individuels (qui ne vont pas contre les objectifs collectifs). La transparence fait que chacun a conscience de l’objectif de l’entreprise, de son business. Et chacun en est responsable.
Alors maintenant, qu’allez-vous faire ? Allez-vous continuez à subir ou allez-vous prendre votre vie en main (en intégrant une société coopérative) ?
]]>En bon petit développeur Java, Gérard garde sa petite idée pour lui, développe la nuit et pendant ses congés pour finalement sortir de l’ombre et mettre en ligne THE application (pour l’instant hébergée directement sur son ordinateur personnel)
Et là, vous connaissez la suite, ça fait psssiiichhhhhttt. L’idée n’est pas trop mal mais :
- Elle n’atteint pas exactement la cible
- Il n’existe aucun vecteur pour que le client soit informé du produit
- Gérard n’a pas prévu de façon de gagner de l’argent
- Finalement, l’heure de gloire arrive enfin, un groupe de chinois tombe sur son site et le copie en deux jours… (c’était bien la peine de l’avoir gardé secrète ton idée Gérard ! )
Ce que nous apprend Camille Roux lors de son talk à Devoxx (et sur slideshare) c’est qu’une idée n’a pas de valeur, tout le monde à des idées. Ce qui a de la valeur c’est sa réalisation. Il nous raconte que lors d’un startup week-end, il s’est retrouvé avec six profils « business ». Six business-men qui ne savent pas coder, mais comment allait il pouvoir les occuper ?
Et là surprise, il existe un autre monde, un monde qui n’est pas le monde du développement et qui a aussi des méthodes et des outils qui ont fait leurs preuves.
Lean Canvas
Camille nous présente l’un de ces outils : le « Lean Canvas » et conseil que tous les voyants soient au vert avant de commencer le développement du produit.

- Problem : Quels problèmes résolvez vous ? Moins vous en résolvez, mieux c’est.
- Solution : Quelles solutions apportez vous ? Moins vous en apportez, mieux c’est.
- Key Metrics : Quels seront les indicateurs qui vont vous permettre de valider le succès de votre idée ? (Ex : le nombre de visites, d’utilisateurs ou de produits vendus)
- Unique Value Proposition : Qu’est-ce que vous apportez que les concurrents n’apportent pas ?
- Unfair advantage : Pourquoi on ne pourra pas vous copier facilement (Ex : une image de marque)
- Customer segments : Votre cible (Ex : La gamine de 13 ans avec un forfait bloqué à dépenser)
- Channels : Comment allez-vous atteindre votre cible ? (Ex : j’ai déjà un site qui fait 10 000 visites de ma cible par jour)
Pour remplir le tableau n’hésitez pas à parler de votre idée à vos amis, votre famille, au barman du coin ou évidemment à des représentant de votre cible. Une fois que tous les indicateurs sont au vert, vous vous rendrez compte que votre idée initiale n’est pas tout à fait la même qu’au départ, elle est largement meilleure.
Ce qui est marrant c’est que je me suis exercé à cette technique sur plusieurs types de projets et à chaque fois cela m’a apporté quelque chose. Même sur un projet open-source, même sur un projet d’entreprise de type « service ».
Pour aller plus loin :
- Running Lean: Iterate from Plan A to a Plan That Works
- Business Model Generation: A Handbook for Visionaries, Game Changers, and Challengers
Tester son idée
Maintenant que l’idée de Gérard a été retravaillée, il est temps de commencer à coder ! Enfin presque, pour tester une idée, un prototype c’est bien, mais il existe d’autres façons :
- Le questionnaire: Faites en un ! Pour savoir notamment si quelqu’un serait prêt à payer pour telle ou telle fonctionnalité. Ainsi vous pourrez démarrer avec la fonctionnalité qui a le plus de valeur et peut-être même avec déjà des clients !
- Sortez ! C’est en sortant, en allant voir vos futurs utilisateurs que vous aurez de nouvelles idées d’améliorations de votre produit, en voyant comment ils travaillent et quels sont leurs problèmes.
- Un article de blog: Si je blogue sur mon idée et que ça buzze, c’est que je suis certainement sur la bonne voie. C’est aussi une façon d’obtenir du feedback.
- Le prototype : Enfin ! Nous allons coder. Mais là encore il s’agit de tester une idée, n’allons donc pas perdre de temps à faire une architecture scalable du feu de dieu, le truc c’est de développer vite mais aussi de développer quelque chose d’agréable à voir. N’hésitez pas à recruter votre pote designer à cette étape là, sinon vous pouvez utiliser Twitter bootstap ou acheter un CSS sur themeforest (c’est ce que j’ai fait pour buildwall.com ). Camille est un développeur Ruby, il nous explique que pour développer une page de type CRUD, il ne faut pas y passer plus de 15min… En Java on ira jeter un oeil à Spring Roo ou Play! framework
Et maintenant, qu’allez-vous faire de vos idées (et de votre vie) ?
]]>
Le pour
– Je suis auteur de mon code, je l’assume et je l’écris de manière professionnelle en pensant à ceux qui vont me lire. C’est une idée que partage Robert C. Martin.
The @author field of a Javadoc tells us who we are. We are authors. And one thing about authors is that they have readers. Indeed, authors are responsible for communicating well with their readers. The next time you write a line of code, remember you are an author, writing for readers who will judge your effort.
– Surtout dans l’open-source, cela permet de laisser une trace de son investissement. Voir de se faire un nom.
– Il peut contenir l’adresse d’une mailing-list, ce qui permet, lors d’une question sur une classe de contacter directement les personnes responsables.
Le contre
– DRY : don’t repeat yourself : l’information est déja présente dans le SCM (git, svn ..).
– Le code appartient à tous : le @author doit donc etre collectif.
– Si il ne contient que l’auteur initial, celui-ci ne vaut pas plus que les autres.
– évite la sacralisation d’un unique développeur
– Pose le problème de savoir quand on doit se rajouter dans la balise @author.
Je laisse à Emmanuel Bernard le tweet de la fin :

Merci à Sébastien PRUNIER @sebprunier, Pierre TEMPLIER @ptemplier, Emmanuel LECHARNY, François Sarradin @fsarradin, Guillaume LOURS @guillaumelours, Jean-Laurent Morlhon @morlhon, Arnaud Héritier @aheritier , Sébastien Deleuze @sdeleuze , Yannick AMEUR @yannickameur , Robin Komiwes @robinkomiwes , Jollivet Christophe @jollivetc , Jérémy Sevellec @jsevellec, Julien Jakubowski @jak78 , Nicolas De loof @ndeloof, Nicolas François @nicofrancois , Francois Marot @FrancoisMarot , Jean Helou @jeanhelou, Benoît Dissert @bdissert , Olivier Jaquemet @OlivierJaquemet , Aline Paponaud @bootis , Benoît Dissert @bdissert , Nicolas Delsaux @riduidel et aux autres …
]]>Pour me préparer aux sélections de code story et pouvoir coder pendant 2 jours une application devant des centaines de développeurs à Devoxx, je me suis entrainé à refactorer une méthode en m’enregistrant.
Le bénéfice que j’attendais de l’exercice était de :
- M’entendre parler pour détecter mes défauts d’expressions et les corriger, car le jour J il faudra expliquer ce qu’on fait et pourquoi, le tout en codant ! Pas facile…
- Maîtriser au maximum mon IDE pour être rapide à coder, rien de plus ennuyeux que de regarder un développeur coder trop lentement !
Pour la petite histoire, je suis partie d’une classe que je venais de refactorer chez un client, il s’agit donc d’un exemple réel. J’ai fait environ 15 essais avant les sélections pour finalement me faire éliminer ! Je suis bon perdant, et je me suis dit que les quelques techniques simples que j’explique pouvaient être intéressantes et que c’était dommage de garder le screencast pour moi. Du coup j’ai refait 5 essais et voici le résultat :
Ce n’est pas parfait ! J’ai même fait une grossière erreur en cassant le comportement de la méthode. Le premier qui trouve où gagne une bière (la date du commentaire faisant foi) ! Si vous trouvez d’autres boulettes ça marche aussi, à l’exclusion de l’utilisation de framework ou de l’API java, Boolean.compareTo par exemple, car ce n’est pas le propos de l’exercice. D’ailleurs s’il y a une chose que je retiens c’est qu’on peut toujours faire mieux !
Pour ceux qui voudrait faire pareil :
- Achetez un bon casque / micro ! (le mien clic! de temps en temps, il faut que j’en rachète un !)
- Sous linux j’utilise Kazam pour l’enregistrement et key-mon pour montrer ce que j’écris.
- Limitez vous à un exercice de moins de 10minutes, on décroche si c’est trop long.
- N’ayez pas honte !
Bon code à tous !
]]> . Cet article ne reprends qu’une partie du talk: les points que j’ai pu rencontrer en entreprise.
1. L’hydre
Hydra est une entité qui a la particularité de contenir une liste immuable de tête (heads.)
@Entity
public class Hydra {
private Long id;
private List heads = new ArrayList();
@Id @GeneratedValue
public Long getId() {...}
protected void setId() {...}
@OneToMany(cascade=CascadeType.ALL)
public List getHeads() {
return Collections.unmodifiableList(heads);
}
protected void setHeads(List heads) {...}
}
// creates and persists the hydra with 3 heads
// new EntityManager and new transaction
Hydra found = em.find(Hydra.class, hydra.getId());
La question est la suivante, combien d’appel sont fait en base de données lors de la deuxième transaction (créer lors de em.find).
(a) 1 select
(b) 2 selects
(c) 1+3 selects
(d) 2 selects, 1 delete, 3
inserts
(e) None of the above
Pendant la recherche, em.find entraine un unique select en base de donnée sur l’hydre.
Pendant le commit qui est effectué à la fin de la transaction, hibernate vérifie que la collection n’est pas dirty, c’est à dire que les objets devraient être recréés en comparant les références objects des listes. Un deuxième select est alors effectué sur les têtes. Dans notre cas, les références ne correspondant pas, l’ensemble de la liste est alors recréé, ce qui explique le delete et les 3 inserts.
Contrairement à ce que l’on pourrait penser dans un premier temps, la bonne réponse est donc la réponse d.
Il faut donc être bien conscient que si on a un objet qui contient une collection et qui porte la liaison, si on affecte une nouvelle liste à l’élément, la collection est recrée entièrement : un delete et n insertions d’éléments. On peut rencontrer également ce genre de problème si on utilise des outils qui suppriment les proxies hibernate sur les objets.
En régle générale, il vaut mieux travailler directement avec les collections retournées par hibernate à moins de savoir ce que l’on fait.
@Entity
public class Developer {
@Id @GeneratedValue
private Long id;
private String mainTechnology;
public boolean likesMainTechnology() {
return "hibernate".equalsIgnoreCase(mainTechnology);
}
}
// creates and persists a developer that uses hibernate as mainTechnology
// new EntityManager and new transaction
Developer dev = em.find(Developer.class, id);
boolean foundCoolStuff = false;
for (String tech : new String[]{"HTML5", "Android", "Scala"}) {
dev.setMainTechnology(tech);
// othersAreUsingIt entraine select count(*) from Developer where mainTechnology = ? and id != ?
if (othersAreUsingIt(tech, dev) && dev.likesMainTechnology()) {
foundCoolStuff = true; break;
}
}
if (!foundCoolStuff) {
// still use hibernate
dev.setMainTechnology("hibernate");
}
(a) 2 selects
(b) 4 selects
(c) 4 selects, 1 update
(d) 4 selects, 4 inserts
(e) None of the above
La bonne réponse est la réponse d, 4 selects et 4 inserts. En effet, hibernate doit garantir la bonne valeur des requêtes exécutées et parfois doit effectuer une flush pendant une transaction. Si on n’effectue plus l’appel à othersAreUsingIt (qui entraine un select sur la table Developer), il n’y a plus d’update.
List semantics
@Entity
public class Forest {
@Id @GeneratedValue
private Long id;
@OneToMany
Collection<Tree> trees = new HashSet<Tree>();
public void plantTree(Tree tree) {
trees.add(tree);
}
}
// creates and persists a forest with 10.000 trees
// new EntityManager and new transaction
Tree tree = new Tree(“oak”);
em.persist(tree);
Forest forest = em.find(Forest.class, id);
forest.plantTree(tree);
(a) 1 select, 2 inserts
(b) 2 selects, 2 inserts
(c) 2 selects, 1 delete,
10.000+2 inserts
(d) Even more
La bonne réponse est la réponse c. La combinaison de l’annotation OneToMany et d’une collection entraine un bag semantic. La collection est donc recrée.
| Semantic | Java Type | Annotation | Add 1 element | Update 1 element | Remove 1 element |
| Bag Semantic | java.utill.Collection java.util.List |
@ElementCollection || @OneToMany || @ManyToMany |
1 delete + n insert | 1 delete + n insert | 1 update |
| Set Semantic | java.utill.Set | @ElementCollection || @OneToMany || @ManyToMany |
1 insert | 1 update | 1 delete |
| List Semantic | java.util.List | (@ElementCollection || @OneToMany || @ManyToMany)&&(@OrderColumn||@IndexColumnn) |
1 insert+ m update | 1 delete + m insert | 1 update |
@OneToMany with no cascade options
La première intuition est de remplacer le Set par une List (List<Tree> trees = new ArrayList<Tree>() ). Néanmoins, cela marche exactement de la même manière.
Le seul moyen de ne pas avoir de bag semantic est d’utiliser orderColumn ou indexColumn
Il faut faire attention à choisir une collection appropriée sur la partie qui contient la liaison. Ainsi dans notre cas, Set<Tree> trees = new HashSet<Tree>() permet d’éviter toutes les insertions parasites.
Utilisation d’un set sur l’object qui ne contient pas la liaison.
@Entity
public class Forest {
@Id @GeneratedValue
private Long id;
@OneToMany (mappedBy = “forest”)
Collection<Tree> trees = new HashSet<Tree>();
public void plantTree(Tree tree) {
trees.add(tree);
}
}
@Entity
public class Tree {
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne
Forest forest;
public void setForest(Forest forest) {
this.forest = forest;
this.forest.plantTree(this);
}
}
// creates and persists a forest with 10.000 trees
// new EntityManager and new transaction
em.remove(forest);
L’appel à em.remove entraine java.sql.BatchUpdateException : cannot delete or update a parent row : a foreign key constraint fails.
Si on garde le modèle, la seule solution est de parcourir l’ensemble des arbres de la forêt et de setter leur forêt à null.
Il est ensuite possible de supprimer la foret. Ce qui entraine 10 000 updates et 1 delete …
D’autres types de collections auraient été plus adéquats.
Il existe beaucoup d’autres anti-patterns. Pour les débusquer dans votre code, il est plus que recommander d’observer attentivement les requêtes ! Les slides sont ici : http://www.yonita.com/2011_11_16_PERFORMANCE_ANTIPATTERNS_DEVOXX.pdf
]]> Rien de prévu mardi prochain ? Rejoignez nous pour la première de la marmite, LA soirée récurrente des duchesses ! J’aurais l’occasion d’animer avec Brice Dutheuil, commiter Mockito, un Hands-On sur la mise en place de tests avec Mockito et comme il y en a pour tous les gouts chez les duchesses, on a également prévu en parallèle un open-space pour échanger sur les sujets qui vous intéressent !
Rien de prévu mardi prochain ? Rejoignez nous pour la première de la marmite, LA soirée récurrente des duchesses ! J’aurais l’occasion d’animer avec Brice Dutheuil, commiter Mockito, un Hands-On sur la mise en place de tests avec Mockito et comme il y en a pour tous les gouts chez les duchesses, on a également prévu en parallèle un open-space pour échanger sur les sujets qui vous intéressent !
Qu’est-ce qu’un open space ? C’est un peu comme un barCamp à part que les sujets sont présentés au début et que l’on ne traite que les sujets les plus populaires pendant un temps limité. Le but essentiel est de partager et de débattre. Tous les sujets autour de Java et de l’IT sont les bienvenus. Pour vous donner des idées, voici quelques pistes possibles :
- une problématique technique que vous avez rencontrée
- un super outil qui a changé votre vie de développeur
- votre sujet de veille préféré
- ou une problématique relationnelle (ex: comment travailler avec une personne au caractère difficile ?).
[wp-simple-survey-1]
]]> Comme beaucoup, il y a eu le passage « classique » en SSII. Pendant 2 ans, j’ai eu l’occasion de rencontrer quelques freelances qui avaient l’air plutôt satisfait. Je me disait qu’ils avaient de la chance et que j’aimerai moi aussi, être indépendante. Tous étaient très expérimentés. Je me disais que j’étais trop jeune et que finalement, la situation de salariée en SSII était confortable. Elle permet à la fois de parfaire mes connaissances techniques et de prendre des contacts durant les missions sans stress.
Comme beaucoup, il y a eu le passage « classique » en SSII. Pendant 2 ans, j’ai eu l’occasion de rencontrer quelques freelances qui avaient l’air plutôt satisfait. Je me disait qu’ils avaient de la chance et que j’aimerai moi aussi, être indépendante. Tous étaient très expérimentés. Je me disais que j’étais trop jeune et que finalement, la situation de salariée en SSII était confortable. Elle permet à la fois de parfaire mes connaissances techniques et de prendre des contacts durant les missions sans stress.
Et puis la chute
Lassée d’être un numéro dans une SSII à taille humaine mais pas vraiment humaine, je me suis laissée tenter par une plus petite structure, seulement quatre personnes. Leur politique se rapprochait de ce que vit un indépendant avec une rémunération variable, indexée sur le prix de vente au client. Le problème d’une petite SSII, c’est qu’on est vendu par une SSII, à une SSII, qui nous place chez un client. Et quand on veux prendre des vacances, il faut demander à 4 personnes…
Finalement placée après 2 semaines de négociation avec les différents interlocuteurs, il était clair que le projet sur lequel je devais travailler ne démarrerait jamais et que je ferais un peu de tout mais rien de ce qui était prévu au départ. Après la ritournelle habituelle des ‘attends au moins 3 mois’ qui se transforment souvent « en attends encore 3 mois de plus », je me suis dit qu’il serait plus facile de sortir de mission si j’en trouvais une autre par moi même.
La surprise
Assez bizarrement, malgré moins de 2 ans d’expérience et en pleine crise mondiale (Avril 2009), j’ai trouvé une mission en moins de 24H. Si moi, pas commerciale pour un sou, je trouvais une mission en moins de 24h, pourquoi continuer à dépendre d’autres personnes pour le faire ? J’ai donc démissionné pour me mettre à mon compte.
Le choix ne fut pas facile pour autant : moi aussi, j’avais un crédit immobilier, sans compter les crédits à la consommation et également un enfant et un conjoint avec une situation pas plus stable que la mienne.
Avec le recul, je me rend compte que tout ça n’est pas un problème, les freelances ont la même vie -ou presque) que les salariés, on a les mêmes contraintes familiales et financières.
Se lancer en tant qu’indépendant est donc uniquement choix : pas de la chance et encore moins du courage. Les contraintes financières ne sont pas un frein dans la grande majorité des cas, et surtout pas pour les juniors, qui n’ont souvent ni famille ni crédit sur les bras.
Et puis, je ne savais pas comment créer une entreprise. En fait, il n’y a rien à faire. Il faut juste trouver une expert comptable et déléguer tout, absolument tout, pour se concentrer sur l’important : son propre métier. Techniquement, ce n’est pas difficile, une lettre de démission et un rendez d’une demi journée chez l’expert comptable et le banquier (pour ouvrir le compte de l’entreprise, pas pour demander la permission !).
Gagner plus ? C’est tout ?
Le premier mythe de mon indépendance a été de croire que l’indépendance c’était uniquement gagner plus. C’est vrai, on gagne plus, j’ai doublé mon revenu net par mois. Mais être picsou, c’est loin d’être mon but dans la vie. Je suis bénévole dans plusieurs associations, ce qui m’occupe entre 3 et 4 jours par mois. J’ai toujours envie de tester les nouvelles technos. J’ai 2 enfants, et comme tout le monde, je n’ai que 24 heures dans une journée.
Et c’est là où il y a eu un changement. J’ai regardé autour de moi. Et j’ai vu :
- Des indépendants picsou, qui bossent un max sans prendre de vacances pour s’arrêter à 35 ans et vivre de leurs rentes. En tant qu’indépendant, on est bien plus maître de son temps de travail. Plus d’obligation de prendre tous ses congés restant au mois de mai, vous gérez votre temps.
- Des indépendants qui préfèrent les missions courtes : le temps entre 2 missions leurs sert à se former, à chercher des clients, mais également à retaper leur maison ou à profiter de la neige. L’intercontrat n’est plus quelque chose de négatif, vous n’êtes plus ‘inactif’, vous pouvez planifier et anticiper vos intercontrats. Et surtout, vous ne vous sentez pas obliger d’accepter une mission.
- Des indépendants qui profitent de la proximité avec le client pour pouvoir négocier plus facilement quelques journées en télétravail contre réduction tarifaire. Ou qui, lorsque le client n’a plus qu’un budget de 3 mois, négocient de rester 6 mois à mi-temps. Être indépendant, c’est également avoir des possibilités de négociation bien plus importante avec le client et donc avoir accès à des aménagements du temps de travail qu’un commercial de SSII n’obtiendrait jamais.
- Des indépendants qui prennent le temps de tester des technos et de partir se former un peu partout, sans limite de temps. Ou qui développent et lancent des projets persos ou Open-Source. Qui écrivent des livres etc …
Et moi et moi ?
J’ai décidé en 2010 de me mettre à mi-temps. Non pas de travailler 1 jour sur 2, c’est assez difficile de trouver des clients qui acceptent ça, mais avoir des intercontrats de plusieurs mois entre 2 missions. Fini le temps de courir. J’ai pu enfin me plonger dans le code source de différents frameworks, lancer mon propre projet, Ensemble-Donnons, qui permet aux petites et moyennes associations de récolter en ligne des donations. Et me former, et profiter de mes enfants.
Prendre sa vie en main
Finalement, être indépendant, ce n’est ni risqué ni difficile. C’est un choix, un choix que même une femme sans expérience peut faire et que vous pouvez faire. Ce choix c’est choisir de pouvoir choisir la façon dont vous voulez travailler. Il faut bien comprendre que plus il a d’intermédiaires qui décident de votre vie, moins vous aurez d’influence. L’intérêt de votre commercial et de votre patron c’est vous leurs rapportiez un maximum d’argent et donc vous placer le plus vite possible même si la mission ne correspond pas vraiment à vos attentes.
Alors, allez-vous finalement prendre vous aussi votre vie en main ?

 http://www.mavieauboulot.fr/
http://www.mavieauboulot.fr/
Cette année, le Paris Java User Group fête ses 3 ans. Pour l’occasion une soirée exceptionnelle est organisée. D’autant plus exceptionnelle que Mathilde viendra raconter comment le statut d’indépendant permet à ceux qui ont fait ce choix de vivre différemment, de vivre mieux.
Tous les détails (lieu, date, programme et inscription) ici : http://www.parisjug.org
]]>
« J’en ai rêvé, je l’ai fait ». Voilà comment je résume mon état d’esprit en ce moment. Je suis Freelance parce que j’ai cette fibre d’indépendance, l’envie de voler par mes propres ailes. Je suis développeur parce que j’aime créer, j’aime réaliser des outils utiles, j’aime réaliser des outils de qualité et j’aime partager mes connaissances (ce blog en est la preuve). En cela je me considère comme un artisan, un « Software Craftsman ».
Après mes études, je voulais déjà fabriquer mon propre produit. A l’époque je souhaitais créer un logiciel pour les campings, ayant baigné dans ce milieu depuis tout petit. Manquant d’expérience et devant l’immensité de la tâche pour un débutant ( 2 débutants en l’occurrence puisque Mathilde était déjà de la partie à cette époque), nous avons mis le projet de coté au bout de 6 mois pour aller apprendre la vie en SSII. Depuis, presque chaque jour j’ai une nouvelle idée, presque chaque jour je suis frustré de ne pas pouvoir la réaliser. J’ai une famille et peu de temps pour réaliser mes idées. Je suis dépendant d’un système, comment développer mes idées sans perdre en revenus, sans faire prendre de risque à mes enfants ?
Rework, tu liras
Au début je me disais qu’il fallait trouver l’idée qui tue, la « killer feature ». Qu’il fallait faire une étude de marché, qu’il fallait des clients, qu’il fallait des investisseurs, qu’il fallait investir aussi et savoir prendre des risques. Qu’il fallait tous développer avant de mettre de publier.
Et un jour j’ai lu :

Avec Rework j’ai compris qu’il fallait démarrer petit. Qu’il fallait résoudre un de ses propres problèmes. Qu’il n’était pas utile de dépenser beaucoup d’argent, ni d’arrêter de travailler, ni de prendre des risques. Qu’il fallait se concentrer sur le cœur du service et rencontrer ses utilisateurs au plus tôt. Mon problème était que toute mes idées, je les chiffrait a plus de 50 jours de travail juste pour le cœur, la résolution basique du problème. Quand je vois que l’idée que j’ai finalement réalisé été chiffré a 4 ou 5 jours et que cela m’a pris plus de 8 jours et qu’il reste encore 2 fois plus de boulot, c’est clairement difficile de tenir la longueur sur un projet de plus de 100 jours.
Des gens, tu rencontreras
Et puis j’ai rencontré des gens, j’ai rencontré Olivier Issaly, un ami de Mathilde, fondateur d’Equideow alors qu’il n’avait pas fini ses études, qui m’a appris que « c’était possible ».
J’ai rencontré Nicolas Martignole, et son express-board, créé en quelques jours avec l’aide des lecteurs de son blog et du framework play!.
Je suis allé à Devoxx, une conférence à ne pas rater, vrai « catalyseur » d’idées et de motivation. Il faut le vivre pour comprendre, allez y
Je suis aussi allé a plusieurs rencontres geek autour de Java, NoSQL, le web sur Paris. A chaque fois j’ai rencontré des gens intéressant qui donne des idées ou nous conforte dans nos idées.
Le web, tu comprendras
Après une mission de 4 ans sur un Framework Java qui me cachais la « réalité du web » à coup d’architecture Statefull, de JSP, taglibs et autre générateur de pages web, je suis arrivé chez Vidal et j’ai re découvert le Web. J’avais déjà mis un pied dans le Web avant Groupama avec PHP. Chez Vidal j’ai découvert la puissance et la simplicité du JavaScript et des architectures Stateless.
Regardez donc les vidéos sur http://www.zengularity.com/ et lisez les premières page de:

pour comprendre à quel point le vrai Web, c’est l’avenir.
Petit, tu commenceras
C’est facile de dire : je vais faire une facebook-like et je vais être riche. Moins facile à faire ! Alors j’ai listé toutes mes idées et je les ai triées de la plus difficile à la plus simple à réaliser et j’en ai déduit « l’idée ». La toute petite idée, tellement simple qu’en un long week end de 4 jours, j’avais le temps de la réaliser. Mon « problème à résoudre » était en fait multiple:
- Accéder au buildwall de Vidal de chez moi ou depuis mon téléphone
- Ne plus perdre les informations du mur chaque fois que le serveur plantait ou qu’on le mettait à jour.
- Ajouter facilement un membre de l’équipe au wall.
Faire un buildwall. Rien de plus simple fonctionnellement. Pour résoudre mes problèmes il suffisait que je porte le projet en un site Internet. Un service sur le cloud, « Software as a Service ».
Cela m’a pris 2 jours pour résoudre les principales problématiques :
- Faire du plein écran en web.
- Trouver le bas d’une page web (pas si simple, une page web n’a pas de fond..)
- Mettre à jour le mur dynamiquement (merci Ajax et le long polling)
Pour cela j’ai utilisé l’excellent Framework Play! avec JQuery, HTML5 et CSS3 pour la partie client. Des ressources REST, MySQL en base de donnée avec Memcache pour optimiser le tout.
Et puis le plus long fut finalement tout le reste :
- la gestion utilisateur
- le design du site
- les mentions légales
- trouver des formules d’abonnement adaptées
- fignoler les détails
Franchement, je ne m’y attendais pas. La bonne surprise fut le CSS, je n’y connaissais rien et j’ai appris très vite. Comme quoi même un 0% artiste peut faire une site correct. Alors pourquoi continuer à faire des Intranets moches ? Go apprendre le CSS !
Je me suis amusé aussi :
- Tout le site est Ajaxifié
- Gestion de l’historique grâce au hash dans l’url, normé par Google pour qu’il puisse crawler le site
- Gestion de la langue. Si votre navigateur est configuré pour voir les sites en anglais, vous verrez le site traduit en anglais !
En production, tu iras
J’ai mis en production 2 semaines après le début du développement. Sans faire de pub dans un premier temps, le temps de faire les derniers réglages. J’ai su stopper mes ardeurs et ne pas démarrer les fonctionnalités annexes et peut être pas utiles (le paiement en ligne par exemple). Il faut que le produit se confronte aux utilisateurs pour comprendre leurs besoins et faire évoluer le site dans le bon sens.
Vous trouverez le site à cette adresse : http://www.buildwall.com N’hésitez pas a participer à son amélioration ! Toute critique ou idée est la bienvenue !
Grand, tu finiras ?
Clairement le but de ce site n’est pas de faire fortune. C’est un premier site, un premier service, une première création qui me permettra de me confronter à la réalité de l’édition de logiciel. J’y ai passé peu de temps finalement et j’ai appris énormément. Je suis donc déjà récompensé !
Comme je l’ai dit j’ai une « liste », j’ai donc un prochain projet, plus difficile à mettre en œuvre. C’est marrant car ce projet je l’ai mais je ne le connais pas, ma liste évoluant sans cesse, je ne peux dire quel projet ce sera lorsque je me déciderai à le commencer.
Tout le monde, tu remercieras
Je tiens vraiment à remercier tous mes collègues et amis (oula ça fait cliché mais c’est pas grave), en fait je suis surpris de n’avoir rencontré personne qui m’a dit « c’est nul, ça sert à rien » mais je ne désespère pas ! Alors dans le désordre, merci :
Jean-Laurent bien entendu pour m’avoir fait découvrir l’agilité, l’intégration continue et l’utilité d’un buildwall. Louis, pour ta relecture, Tony pour ton aide précieuse sur JQuery, Aurélien alias « John » pour ton aide précieuse sur le logo. Mathilde pour t’être occupée des monstres. Merci a tous ceux qui m’ont encouragé, les collègues de Vidal et les personnes rencontrés à Devoxx à qui j’ai présenté le « proof of concept » du produit et qui ont été les premiers à me donner de nouvelles idées.
Merci enfin à tous ceux qui s’inscriront sur http://www.buildwall.com et qui m’aideront à améliorer le produit (ou à le vendre à leur employeur :P)
]]> L’article précédent a permis de comparer la syntaxe des trois frameworks sur les cas classiques. Un cas où Spock se détache vraiment des deux autres frameworks, c’est sur la gestion des arguments des méthodes mockées.
L’article précédent a permis de comparer la syntaxe des trois frameworks sur les cas classiques. Un cas où Spock se détache vraiment des deux autres frameworks, c’est sur la gestion des arguments des méthodes mockées.
Les wildcards
Il est possible d’utiliser des wildcards au niveau des arguments appelés. Ainsi 1 * calendarDao
.getInfosByDay(_) veut dire ‘la méthode calendarDao.getInfosByDay est appelée une fois (1 *) avec n’importe quel paramètre (_). On peut également spécifier la classe de l’argument : 1 * calendarDao.getInfosByDay(_ as String) .
Il est également possible par exemple de compter le nombre d’appel aux méthodes d’un simulacre (quel quel soit : 3 * calendarDao._ passera uniquement si les instructions du bloc when font exactement appel à 3 méthodes de l’instance calendarDao. Il est également possible de donner des intervalles plutôt qu’une valeur, ce qui n’est pas permis par les autres frameworks (à part le ‘au moins 1 fois’) :
(1..3) * calendarDao.getInfosByDay(_) [entre 1 et 3 fois]
(5.._) * calendarDao.getInfosByDay(_) [=> au moins 5 fois]
(_..5) * calendarDao.getInfosByDay(_) [=> au plus 5 fois]
Il existe de nombreux wildcard, la plupart ne servent pas à grand chose. Ceux qui me semblent le plus important :
calendarDao.getInfosByDay(_) : n’importe quel argument
calendarDao.getInfosByDay(!null) : n’importe quel argument non null
calendarDao.getInfosByDay(_ as String) tous les éléments de type String
Equivalent EasyMock
expect(calendarDao.getInfosByDay((String)anyObject())) : n’importe quel argument, obligation d’être une String
expect(calendarDao.getInfosByDay((String)notNull())): n’importe quel argument non null
expect(calendarDao.getInfosByDay(isA(String.class))):tous les élements de type String
Equivalent Mockito
when(calendarDao.getInfosByDay(anyString())) : n’importe quel argument, obligation d’être une String
when(calendarDao.getInfosByDay((String)notNull())): n’importe quel argument non null
when(calendarDao.getInfosByDay(isA(String.class))): tous les élements de type String
Vous pouvez trouver la liste ici : http://code.google.com/p/spock/wiki/Interactions
Les contraintes personnalisées
Les contraintes personnalisées sont très utiles dans certains cas, par exemple lorsque la méthode equals est déjà défini dans le code et qu’elle ne correspond pas à notre besoin ou que nous avons par exemple un champ date que nous souhaitons exclure de la comparaison. En règle général, il vaut mieux redéfinir la méthode equals qui est spontannément utilisée par les 3 frameworks pour comparer l’égalité des arguments attendus et reçus.
Nous allons chercher avec les 3 frameworks à créer des contraintes personnalisés (spock) ou des argument matcher (Mockito & Easymock). Notre but est de faire en sorte que l’appel à listSpockData.add avec un paramètre ayant comme variable de classe img égale à « a » soit bien simulée. Pour cela, nous créons un objet spockData ayant bien img = « a » ainsi qu’une liste d’objets SpockData. Nous appelons ensuite la méthode listSpockData avec l’objet spockData et vérifions que cette dernière a bien été appelée.
Avec Spock :
def "should list Spock Data"() {
given:
SpockData spockData = new SpockData("a", "accroche", "details", 6);
List listSpockData = Mock();
when :
listSpockData.add spockData;
then :
1*listSpockData.add({it.img=="a"})
}
Spock permet via les conditions particulières de définir un bloc à l’aide d’une closure , avec { } et de définir à l’intérieur plusieurs conditions. It signifie ici l’objet qui sera passé en paramètre à la méthode. Il est possible d’utiliser plusieurs expression (it.img== »img »&&it.day==6) ou une fonction définie dans la classe de test.
Avec Mockito, qui utilise en fait les ArgumentMatcher du framework Hamcrest.
class isImgEqualToA extends ArgumentMatcher { //creation d un argument matcher
public boolean matches(Object spockData) {
return ((SpockData) spockData).getImg() == "a";
}
}
@Test
public void testArgumentMockito(){
List mock = mock(List.class);
when(mock.add(argThat(new isImgEqualToA()))).thenReturn(true);
mock.add(newSpockData("a", "b", "c", 2));
verify(mock).add(argThat(new isImgEqualToA()));
}
Avec Easymock, l’opération se révèle être très verbeuse. [Pour voir une implémentation plus conforme] :
static class Matcher implements IArgumentMatcher { //creation du matcher
@Override// implementer cette methode permet de definir
// un message d erreur
public void appendTo(StringBuffer arg0) {
}
@Override// definition de la methode qui verifiera que
// l argument img est bien egal a A. smell code.
public boolean matches(Object spockData) {
return ((SpockData) spockData).getImg() == "a";
}
// definition d une methode static pour déclarer le matcher
public static SpockData isImgEqualToA() {
EasyMock.reportMatcher(new Matcher());
return null;
}
}
@Test //Test
public void testArgumentEasyMock() {
List mock = createMock(List.class);
expect(mock.add(Matcher.isImgEqualToA())).andReturn(true);
replay(mock);
mock.add(new SpockData("a", "b", "c", 2));
verify(mock);
}
Les tests mockito et easymock sont bien plus verbeux et au final sont plus restrictifs car elles utilisent des classes séparées pour définir les matchers. Spock évite la lourdeur d’avoir à définir une autre classe
Néanmoins, dans le cas de tests avec ArgumentMatcher, EasyMock & Mockito permettent de définir des messages d’erreurs personnalisés, via la méthode appendTo pour le premier et describeTo pour le deuxième. Notons que pour le premier, il faut la coder nous même alors que le deuxième en propose une par défaut construite à partir du nom de la classe isImgEqualToA donne ‘Img equal to A’. En règle général, on affiche un toString() de l’objet pour aider au debuggage et on regarde alors les 2 chaînes pour trouver les différences (ou en pas à pas en debug). Spock ne propose rien de tel dans sa version actuelle (0.4) mais en version 0.5 il est prévu de pouvoir utiliser les matchers d’Hamcrest, revenant à avoir la même syntaxe qu’avec Mockito, en un peu plus courte.
Crédit Photo : Oskay – http://www.flickr.com/photos/oskay/339996940/sizes/m/in/photostream/
]]> On a vu dans la première partie que l’on pouvait faire facilement du data-driven testing et que la syntaxe en bloc apportait beaucoup en lisibilité. Les blocs expect/where que l’on a vu sont les plus adéquats lors de cas de tests simples, où l’on peut facilement exprimer le stimulus et son résultat, typiquement monojbetA.maMethode()==monResultat. Dans le cas où l’on se retrouve face à des tests un peu plus compliqués, l’utilisation de la structure given/when/then est alors préférable. Cet article n’a pas pour vocation de comparer les fonctionnalités des trois frameworks, juste de présenter spock et de comparer la syntaxe des trois frameworks dans le cas de tests ‘classiques’.
On a vu dans la première partie que l’on pouvait faire facilement du data-driven testing et que la syntaxe en bloc apportait beaucoup en lisibilité. Les blocs expect/where que l’on a vu sont les plus adéquats lors de cas de tests simples, où l’on peut facilement exprimer le stimulus et son résultat, typiquement monojbetA.maMethode()==monResultat. Dans le cas où l’on se retrouve face à des tests un peu plus compliqués, l’utilisation de la structure given/when/then est alors préférable. Cet article n’a pas pour vocation de comparer les fonctionnalités des trois frameworks, juste de présenter spock et de comparer la syntaxe des trois frameworks dans le cas de tests ‘classiques’.Test given/when/then
En effet, un bloc then permet de déclarer des conditions, des exceptions, des interactions et des définitions de variables là où un bloc expect ne peut contenir que des conditions et des déclarations de variables. L’écriture given/when/then est également plus intuitive dans le cas où vous souhaitez tester des stories. C’est également une des clés du Behavior Driven Development et une méthode saine pour structurer ses tests, qui oblige à réfléchir vraiment à ce que l’on teste. Ce que j’aime chez spock, c’est que c’est obligatoirement intégré via ces blocs, on ne peut pas faire autrement
Test condition simple – comportement
Spock permet le data-driven testing mais c’est également un framework facilitant la création de bouchons/simulacres [Plus d’infos sur les différences bouchon/simulacre et test d’état/de comportement]. On s’intéresse ici au le test par comportement, c’est à dire qu’on va s’occuper des chainages des appels des méthodes entre elles et moins du résultat. On cherche alors à vérifier que l’appel à spockResource.findCalendarByDay(‘1’) entraîne bien un unique appel à calendarDao.getInfosByDay(‘1’).
def "test par comportement"() {
given:
def calendarDao = Mock(CalendarDao)
def spockResource = new SpockResource(calendarDao)
when :
spockResource.findCalendarByDay("1")
then :
1 * calendarDao.getInfosByDay("1")
}
Le bloc given permet de définir les variables nécessaires à l’exécution du test. Ici, on bouchonne le dao que l’on affecte ensuite au service que l’on souhaite tester. Le bloc when correspond à l’appel de la méthode à tester.
Le bloc then comporte ici uniquement la condition à tester. La syntaxe veut dire on vérifie que la méthode calendarDao
.getInfosByDay est appelée uniquement une fois (1 *) avec le paramètre ‘1’. Les paramètres sont évalués via l’appel à la méthode equals.
A la différence d’EasyMock, qui fonctionne par défaut avec des simulacres, Spock comme Mockito renvoie de base pour toutes les méthodes mockées sans spécification null ou 0 ou false. Ici par exemple, l’appel à
calendarDao
.getInfosByDay("1")
renverra null. Pour spécifier une valeur de retour différente, il suffit d’utiliser la syntaxe suivante :
calendarDao
.getInfosByDay(_) >> new SpockInfo("1");
Le même code avec EasyMock avec une valeur de retour :
@Test
public void testEasyMock() {
//given
CalendarDao calendarDao = createNiceMock(CalendarDao.class);
SpockResourcespockResource = new SpockResource(
calendarDao);
expect(calendarDao.getInfosByDay("1")).andReturn(
new SpockInfo("1"));
replay(calendarDao);
//when
SpockInfo spockInfo= spockResource.findCalendarByDay("1");
//then
verify(calendarDao);
}
Avec EasyMock, on annote la méthode par @Test [annotation JUnit] puis on crée le mock à l’aide de EasyMock.createNiceMock, pour avoir un mock lénient. On précise ensuite que l’on s’attend à ce que la méthode calendarDao.getInfosByDay(‘1’) retourne l’objet new SpockInfo(‘1’) avec expect(calendarDao.getInfosByDay(‘1’)).andReturn(new SpockInfo(‘1’)); . On ‘charge’ ensuite les mocks via le replay et à la ligne suivante on lance l’appel à la méthode testée. Le verify à la dernière ligne permet de vérifier qu’un unique appel à la méthode a bien été effectué.
Test condition simple – état
L’inconvénient de l’utilisation des simulacres, c’est que les tests et le code testé sont très (trop!) liés. Ainsi une modification du code peut entraîner beaucoup de refactoring au niveau des tests sans valeur ajouté. L’exemple le plus marquant est la séparation d’une méthode en deux méthodes distinctes : il faut reprendre tous les simulacres alors que ce n’est qu’une modification de ‘clarté’. Il est donc souvent préférable de ne pas tester le comportement mais uniquement le résultat à chaque fois que cela est possible et judicieux, c’est à dire du faire du test sur l’état des objets.
def "test stub avec retour"() {
given:
def calendarDao = Mock(CalendarDao)
def spockResource = new SpockResource(calendarDao)
when :
def spockInfo = spockResource.findCalendarByDay("1")
then :
calendarDao
.getInfosByDay("1") >> new SpockInfo("1");
spockInfo.day == 1
}
Ici, on ne fait plus de contrôle sur le nombre d’appel à la méthode getInfosByDay(‘1’). On indique juste que lorsque cette méthode est appelée, on renvoie (>>) une nouvelle instance de SpockInfo. Ici pas de assertEquals ou autre méthode du genre, le spockInfo.day==1 est en fait un raccourci pour écrire assert spockInfo.day == 1.On vérifie que la variable day de l’objet spockInfo est bien égale à 1.
Voilà le code équivalent avec Mockito :
@Test
public void testMockito() {
//Given
CalendarDao calendarDao = mock(CalendarDao.class);
SpockResource spockResource = new SpockResource(
calendarDao);
when(calendarDao.getInfosByDay("1")).thenReturn(
new SpockData("1"));
//when
SpockData spockData= spockResource.findCalendarByDay("1");
//then
assertEquals("1", spockData.getDay());
}
A la première ligne, on construit le bouchon calendarDao que l’on affecte à la ligne suivante à l’objet spockResource. On indique au bouchon calendarDao que quand la méthode getInfosByDay est appelée avec le paramètre ‘1’, alors elle retourne new SpockData(‘1’). On effectue ensuite l’appel à la méthode testée spockResource.findCalendarByDay(‘1’) et on vérifie que la variable day du résultat spockData est bien égale à 1.
Et si on veut chainer les retours ?
Test retour multiple
Il est parfois nécessaire de renvoyer des valeurs différentes pour une même méthode bouchonnée. Pour les 3 cas suivants, le premier appel à la méthode calendarDao.getInfosByDay avec le paramètre ‘1’ renverra SpockInfo(‘1’), le deuxième new SpockInfo(‘2’) :
Avec Easymock :
expect(calendarDao.getInfosByDay("1")).andReturn(new SpockInfo("1")).andReturn(new SpockInfo("2"))
Avec Mockito :
when(calendarDao.getInfosByDay("1")).thenReturn(new SpockData("1")).thenReturn(new SpockInfo("2"))
Avec Spock :
calendarDao.getInfosByDay("1") >>> [new SpockInfo("1"),new SpockInfo("2")];
Le prochain article abordera les fonctionnalités plus avancées de la gestion des arguments des fonctions mockées (ArgumentMatcher) également dans les trois frameworks.
Crédit Photo : Mistinguette18
]]> Au cours de mes tribulations, je suis tombée sur un nouveau framework de test : Spock, basé sur Groovy & JUnit. Il est facile à prendre en main et est beaucoup moins verbeux que certains autres framework de tests même quand on ne maitrîse pas Groovy. Les tests sont structurés à l’aide de blocs given/when/then et setup/expect/where ce qui permet d’améliorer la lisibilité et l’écriture. Ce framework est à suivre, il est rapidement pris en main mais il manque encore certaines fonctionnalités avancées. Cet article est le premier d’une série de trois, il permettra de comparer spock à d’autres frameworks similaires.
Au cours de mes tribulations, je suis tombée sur un nouveau framework de test : Spock, basé sur Groovy & JUnit. Il est facile à prendre en main et est beaucoup moins verbeux que certains autres framework de tests même quand on ne maitrîse pas Groovy. Les tests sont structurés à l’aide de blocs given/when/then et setup/expect/where ce qui permet d’améliorer la lisibilité et l’écriture. Ce framework est à suivre, il est rapidement pris en main mais il manque encore certaines fonctionnalités avancées. Cet article est le premier d’une série de trois, il permettra de comparer spock à d’autres frameworks similaires.Premier test setup/expect/where
def "String param should correspond to numeric spockInfoDay - classical syntax"() {
setup:
def spockResource = new SpockResource(new CalendarDaoStatic())
expect:
spockResource.findCalendarByDay(day).day == dayNumeric
where:
day << ["1", "2", "3"]
dayNumeric << [1, 2, 3]
}
Le test est organisé en 3 blocs : setup, expect et where le tout placé dans un objet dont le nom est défini par def « nom du test ». Le premier bloc setup sert à déclarer les variables qui vont être utilisées dans la suite du test. Ici c’est par exemple l’instanciation de l’objet spockResource. Dans le bloc where, je définis deux variables : l’une day qui prendra successivement les valeurs ‘1’,’2′ et ‘3’ et l’autre dayNumeric les valeurs 1,2,3 [groovy est un langage dynamique donc pas besoin d’indiquer le type des variables, il sera déterminé automatiquement]. Dans le bloc expect, j’indique mon test : je vérifie que la méthode spcokResource.findCalendarByDay retourne bien un objet comportant un attribut day dont la valeur correspond à la valeur en tant qu’entier d’une chaîne de caractère [c’est à dire que ma fonctionnalité ne fait pas grand chose d’autre qu’un Integer.valueOf]. Lors de l’exécution, il y a en réalité 3 tests JUnit qui sont exécutés, un pour chaque couple de paramètre day=’1′ & dayNumeric=1 / day=’2′ & dayNumeric=2 / day=’3′ & dayNumeric=3
Test avec structure en tableau
Le même test peut être écrit d’une manière différente en utilisant une autre syntaxe, encore plus lisible.
def "String param should correspond to numeric spockInfoDay"() {
setup:
def spockResource = new SpockResource(new CalendarDaoStatic())
expect:
spockResource.findCalendarByDay(day).day == dayNumeric
where:
day | dayNumeric
"1" | 1
"2" | 2
"3" | 3
}
Ici même principe, 3 tests seront joués , avec les paramètres day = ‘1’ et dayNumeric = 1 / day = ‘2’ et dayNumeric = 2 /day = ‘3’ et dayNumeric = 3 . Les paramètres étant les uns à la suite des autres et séparés par des | cela permet de mieux visualiser ses données de test.
Le choix entre la première et la deuxième méthode dépend du contexte. Si les données à tester sont statiques, la deuxième méthode est plus claire. Mais la première méthode permet de tester avec des données dynamiques comme par exemple :
where:
[a, b, c] << sql.rows("select a, b, c from maxdata")
Ces deux syntaxes permettent de faire du data-driven testing, c’est à dire du test piloté par les données : il est possible de vérifier plusieurs test cases en injectant les données de départ et les données attendues via une source externe, ici le bloc where. Nettement plus simple que de lancer trois tests JUnit différent pour le même comportement, le tout en restant très lisible.
JUnit
Si on regarde l’équivalent JUnit
@RunWith(Parameterized.class)
public class DataDrivenSimpleTest {
private Integer day;
private Integer dayNumeric;
@Parameters
public static Collection data() {
return Arrays.asList(new Object[][] { { 1, 1 }, { 2, 2 },
{ 3, 3 } });
}
public DataDrivenSimpleTest(Integer day, Integer dayNumeric) {
super();
this.day = day;
this.dayNumeric = dayNumeric;
}
@Test
public void shouldReturnTheNumericValueOfDay() {
FoetusCalendarResource calendar = new FoetusCalendarResource(
new CalendarDaoStatic());
assertEquals(calendar.findCalendarByDay(day).getNbJour(), dayNumeric);
}
}
Voilà l’exemple avec l’annotation @Parameters incluse dans JUnit depuis la version 4.0 et il n’y a que l’essentiel pour tester la méthode findCalendarByDay. Tout d’abord, la classe doit être lancée avec un runner spécifique Parameterized.class (à la ligne 1). Elle a besoin de deux variables de classes day et dayNumeric ainsi que d’un constructeur qui initialise ses deux variables. Il y a aussi besoin d’une méthode public static qui retourne une collection d’object représentant les différentes données pouvant être prises par les deux paramètres day et dayNumeric annotée avec @Parameters. Seulement ensuite apparait la méthode de test, shouldReturnTheNumericValueOfDay qui utilise les variables de classes day et dayNumeric. Il est également possible dans la méthode annotée par @Parameters de définir de manière dynamique des jeux de données, on peut par exemple penser à l’importation de données à partir d’un fichier excel ou d’une requête SQL par exemple comme avec Spock. Outre la verbosité de cette méthode, il n’est possible que d’avoir un seul test paramétré par classe.
Les pré-requis à l’utilisation des tests paramétrés avec JUnit (variables de classe, runner, constructeur …) font que je préfère largement utiliser Spock pour faire du data-driven testing.
]]> Qui n’a jamais attendu de nombreuses minutes pour builder un projet ? Et qui n’en a jamais profité pour aller boire un café/regarder twitter/… ? Parce que l’on teste fréquemment, il est important d’essayer d’optimiser et de réduire la durée d’exécution des tests. Tester souvent ne veux pas dire attendre souvent ! Il est donc primordial d’essayer de réduire cette durée en jouant sur différents paramètres. Comment obtenir le résultat des tests le plus rapidement possible ?
Qui n’a jamais attendu de nombreuses minutes pour builder un projet ? Et qui n’en a jamais profité pour aller boire un café/regarder twitter/… ? Parce que l’on teste fréquemment, il est important d’essayer d’optimiser et de réduire la durée d’exécution des tests. Tester souvent ne veux pas dire attendre souvent ! Il est donc primordial d’essayer de réduire cette durée en jouant sur différents paramètres. Comment obtenir le résultat des tests le plus rapidement possible ?
Ce qui suit est tiré de la conférence de David Gageot [ @dgageot / http://javabien.net ] à SoftShake 2010.
Sur une vingtaine de personnes présentes dans la salle, les durées de build vont de quelques minutes à plusieurs heures. David présente brièvement quelques frameworks comme Infinitest et JUnitMax. Ce sont des plugins pour IDE Java qui permettent de lancer les tests unitaires en continu et de manière intelligente, c’est à dire uniquement ceux impactés par le code modifié.
La première idée lorsque l’on cherche à optimiser cette durée d’exécution, c’est de vouloir déléguer le problème. C’est faire tourner les tests sur des serveurs distribués qui permettront d’exécuter les tests en tâches de fond. C’est une mauvaise idée, les serveurs coûtent chers et on peut se retrouver submerger. Il existe des méthodes plus simples pour réduire cette durée.
Le KISS ( Keep It Simple, Stupid ) est également applicable lorsque l’on crée des tests. Chercher à optimises ses tests peut améliorer votre produit : ce qui est simple à tester sera simple à coder et à utiliser. Ce qui est compliqué n’en vaut surement pas la peine.
Le tricheur
La manière la plus simple pour accélérer les tests c’est d’acheter une machine plus rapide. Exécuter les tests sur une machine plus rapide peut être un vrai gain de temps, David nous donne l’exemple d’une exécution 15% plus rapide sur la machine la plus rapide par rapport à la plus lente. Il est également possible d’utiliser la nouvelle fonctionnalité de maven de build en parallèle (mvn -T2 clean install / mvn -t4 clean install). Nous avons essayé sur un de nos projets, l’exécution du build est passé de 1m30 à 30 secondes !
Il est également possible de faire en sorte que les tâches maven surefire pour JUnit et TestNG soient exécutés en parallèle. Comme les tests se doivent d’être indépendant et isolés, ce sont de bons candidats à une exécution en parallèle. Faire quand même attention que vous pouvez vous retrouver avec des problèmes de concurrence dans certains cas.
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.5</version>
<configuration>
<parallel>methods</parallel>
<threadCount>4</threadCount>
</configuration>
</plugin>
Il existe deux façons de paralléliser : méthodes ou classes. Utiliser la méthode de parallélisation par méthode peut se révéler risqué car il est fort probable que tous les tests n’auront pas été designés dans l’optique d’être exécutés en parallèle, la méthode ‘classes’ est un choix plus prudent. Plus d’infos sur le blog de Wakaleo Consulting.
Le paresseux
Il y a souvent des tests redondants dans un projets : débusquez les, cela permettra de gagner en exécution et en lisibilité. C’est tellement simple qu’on ne le fait pas ! Ne pas hésiter à supprimer des fonctionnalités et les tests associés si elles ne servent plus rien, le projet y gagnera en simplicité.
Les accès réseaux et disques sont trop lents. Il faut essayer au maximum de s’en passer et privilégier les bases de données en mémoire comme h2 (qui ressemblera plus à mysql que hsqldb). De même pour les accès mails, il est possible d’utiliser dans les tests des serveurs SMTP en mémoire comme ethereal. Si beaucoup de tests accèdent à des fichiers, Spring Resource ou Apache VFS (Virtual File System) sont de bonnes alternatives.
Le brave
Il est préférable de tester les règles métiers dans les tests unitaires plutôt que dans les test d’intégrations. Il ne faut pas confondre tests d’intégrations et tests unitaires : les premiers sont , bien qu’essentiel, plus longs à tester, ils doivent être utiliser avec parcimonie. Par exemple, pour plusieurs tests qui accèderaient à une base de données peuvent être remplacés par un test qui permet de garantir que l’on peut bien accéder à la base de données et par plusieurs autres tests où l’accès à la base de données aura été bouchonné.
Une méthode lorsque l’on cherche à diminuer la durée d’exécution de tests est de prendre le test d’intégration le plus long et de l’analyser jusqu’à réussir à le découper en un test d’intégration plus petit et plusieurs tests unitaires. Si c’est l’accès à certaines couches qui sont lentes lors de tests d’intégrations, il est recommandé de les bouchonner, les frameworks de mocks ne servent pas que dans le cas de tests unitaires
De même, méfiez vous des tests d’interface, ils prennent beaucoup de temps et souvent, ce qu’ils testent peut être tester unitairement. Selenium est à utiliser avec modération. Méfiez vous vraiment quand vous commencez à tester vos fonctionnalités via Selenium. Et ne dites pas ‘mon utilisateur veut de l’AJAX‘ ‘J’ai besoin de tester la compatibilité des différents navigateurs’.
Chaque complexité a un coût. Et cela se paye à chaque fois que les tests sont exécutés. Si c’est compliqué à tester : danger, la fonctionnalité peut sûrement être faite plus simplement. Il est possible de faire des tests unitaires en Javascript plutôt que tester dans les browsers (ex : QUnit).
David préfère limité AJAX aux réels besoins et d’effectuer au maximum le code server-side.
Et pour finir : simplifier et optimiser votre code. Ce sont des choses qui se font. Le build va être plus rapide et l’application aussi  A vous l’effet Kiss Cool
A vous l’effet Kiss Cool

JRebel est un outil payant permettant d’effectuer des rechargements à chaud d’applicatif Java. C’est clairement l’outil qui fera de vous un développeur plus productif. Voilà une bonne façon de se faire bien voir, de rentrer plus tôt à la maison ou d’augmenter sa facturation
Vous pouvez, en tant que personne, acheter une « Personnal license » et l’utiliser dans le cadre de votre travail. Cette licence ne peut pas être remboursée par votre entreprise. L’achat d’une licence « standard » n’est pas rentable, même payé par votre EURL. Votre client peut également acheter des licences standard mais personnellement, je pense qu’il vaut mieux lui permettre de faire cette économie. Un client n’est pas éternel et un geste commercial est toujours bien vu non ?
Fonctionnement
JRebel est ce que l’on appelle un « java agent » (see : http://blog.xebia.fr/2008/05/02/java-agent-instrumentez-vos-classes/ ). C’est à dire qu’il va instrumenter le bytecode.
Pour que cela fonctionne il faudra donc spécifier à la JVM l’agent JRebel (jrebel.jar).
Cette agent fonctionne de manière très simple, il scrute le classpath à la recherche des fichiers rebel.xml. Ces fichiers permettent de faire un mapping entre l’application (bytecode et ressources) et votre code source. JRebel scan les sources et les mets à jour dans l’application en cours d’exécution. C’est aussi simple que cela.
Vous l’avez compris, pour recharger à chaud votre projet et toutes vos dépendances vous devez avoir un fichier rebel.xml dans chacun des projets (.jar .war) que vous souhaitez recharger à chaud.
Installation
L’installation de JRebel va simplement copier l’agent jrebel.jar dans le répertoire de votre choix. Il existe également un plugin Eclipse (optionnel).
Comme nous l’avons vu, nous devons fournir un fichier rebel.xml dans chacun de nos projets. Avec Maven, il suffit simplement d’ajouter le plugin maven-rebel, dans le fichier pom.xml :
<plugin>
<groupId>org.zeroturnaround</groupId>
<artifactId>javarebel-maven-plugin</artifactId>
<version>1.0.5</version>
<executions>
<execution>
<id>generate-rebel-xml</id>
<phase>process-resources</phase>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
</plugin>
On pourra lancer la génération manuellement via « mvn javarebel:generate »
Ensuite, il suffit de lancer l’application en spécifiant l’agent à la JVM :
-noverify
-javaagent: »C:Program FilesZeroTurnaroundJRebeljrebel.jar »
Si vous lancer votre application via maven (mvn jetty:run par ex), vous pouvez utiliser la variable système MAVEN_OPTS, ou utiliser « Run configuration » dans Eclipse. Il doit sans doute exister un moyen de le faire dans le pom (via un profil « rebel » par exemple).
Voilà ça fonctionne !
Have fun !
]]>
Au début de ma carrière, je me souviens qu’un de mes collègues m’a dit « Tu sais, au final, on se rend compte qu’il n’y a que très peu de différence de productivité entre un bon développeur et un développeur lambda ». Je l’ai cru, et il m’a fallu quelques années pour me rendre compte qu’il avait complétement tort. Un développeur productif peu produire jusqu’à 10 fois plus (sans diminuer la qualité du code). Sachant que les tarifs vont du simple au double, engager un bon développeur, 2 fois plus cher, peut s’avérer en fait 5 fois plus rentable pour le client. Pensez y au prochain entretien
A votre avis, un client préférera prendre un développeur productif mais cher ou un développeur lambda pas cher ?
Apprendre en continu
Le seul moyen de s’améliorer c’est d’apprendre, apprendre, apprendre. N’hésitez pas à poser une journée ou deux par mois, et de préférence en semaine pour vous former au calme, chez vous. Les transports sont aussi une bonne occasion, pour ceux qui ont la chance de les utiliser.
Ce n’est que quand j’ai commencé à m’ennuyer en mission que j’ai décidé de lire. Et c’est en lisant que je me suis rendu compte à quel point j’étais mauvais en Java. Le livre qui m’a fait prendre conscience est « Effective Java » :

Bien, une fois que j’ai pris conscience qu’en fait j’avais rien compris à Java, suis je meilleur développeur ? Non, mais c’est un début. Maintenant il faut apprendre se comporter comme un bon développeur. Que ce soit avec votre code : « Don’t repeat yourself », avec les autres : « Provide Options, Don’t Make Lame Excuses » ou avec vous même : « Invest Regularly in Your Knowledge Portfolio »
« The pragmatic programmer » est LE livre à lire et se présente sous la forme d’une liste d’astuces :

Dans le même style, les astuces sont plutôt orientées Business mais certaines peuvent s’appliquer à nos développements. Et puis, quel freelance ne rêve pas de monter sa petite entreprise ? Rework est le genre de livre qui peut révolutionner une vie :
Et après ?
Voici une liste d’astuces, issue de ma propre expérience.
– Maîtriser vos outils : Apprenez les raccourcis clavier de votre IDE et utilisez les. Regarder comment les autres développeur utilisent vos outils, c’est très instructif !
– Choisissez vos missions : Débrouiller vous pour toujours travailler avec des gens meilleurs que vous. Faites en sortes de toujours apprendre quelque chose de nouveau (technos, architecture, langage, métier, méthodologie).
– Reposez vous : Inutile de se fatiguer au travail, cela ne fera que baisser votre productivité. Fatigue = erreurs. Un besoin incompris, c’est une productivité nulle.
– Changez vous les idées, consacrez du temps à vos loisirs et à votre famille. Cela boostera votre créativité et vous aidera à résoudre les problèmes complexes.
– Limitez les sources de perturbations. Coupez Twitter, votre e-mail (même le pro) ainsi que Facebook. Profitez de votre téléphone 3G dernier cris pour traiter tous ça dans les transports le matin et le soir.
– Travaillez vos forces et laissez tomber vos faiblesses : Est ce bien utile de s’obstiner à maîtriser CSS et photoshop alors que l’on n’est pas artiste pour un sou ? Cela va vous prendre énormément de temps. Temps qui serait mieux utilisé à augmenter votre expertise dans votre domaine de compétence. Ne soyez pas dupes et ne soyez pas jaloux des « rockstar », vous êtes sans doute meilleur qu’eux dans un autre domaine !
Livres Bonus
Pour ceux qui vont vite et aussi parceque cet article est l’occasion de tester les liens sponsorisés Amazon ;), voici 3 livres qui m’ont également aidé à progresser et que je vous conseil pour compléter votre read list:



YapluKa !
]]>Pourquoi ?
Malgré une famille, un crédit maison sur 15 ans et un crédit auto sur 6 et une expérience de 2/3 ans, j’avais envie de découvrir autre chose que le monde des SSII.
Mes expériences en SSII ne sont pas négatives, une SSII de taille moyenne grâce à laquelle j’ai pu faire une mission très intéressante mais pas vraiment au point pour entretenir une communauté de développeur en son sein et y favoriser le partage des connaissances. Une tout petite SSII où au final je ne serai restée que quelques semaines mais dont l’obligation de sous-traitance à d’autres SSII plombe le modèle économique et là encore pas assez de matière pour aider en interne à monter en compétence. Au niveau de la plupart des SSII, celles ci apportent effectivement une certaine sécurité au niveau de l’emploi (valeur tellement ancrée dans la société…). Mais tout a un prix.
J’avoue que les traditionnels arguments tels que cités ici ne m’ont pas vraiment touché. L’aspect financier n’est clairement pas le plus important, juste je ne comprends plus bien l’intérêt d’être dans la plupart des SSII. Une grosse majorité de gens me disent spontanément qu’ils vont passer freelance dans X années, mais j’ai vraiment l’impression que très peu de junior (1/2 d’expérience) se lancent.
Comment ?
Pour me lancer, rien de bien difficile et pourtant, c’était en Mai, autrement dit, dans la période la plus critique vis à vis de la crise.
J’ai crée mon CV sur freelance-info.fr et au bout de 2 heures, un premier commercial m’a contacté pour une mission qui m’avait l’air intéressante et pour laquelle on a vite convenu d’un rendez vous. Une heure après, un deuxième commercial m’appelait. Et ainsi de suite, ça ressemble un peu à ce qu’on vit quand on met son CV sur Monster …
Les rendez vous avec le commercial puis avec le client se sont effectués dans la foulée. La mission a commencé deux semaines plus tard.
Ce qui ne change pas
Au bout d’un an, je n’ai pas vu de différence avec mes 3 missions en SSII et ma mission actuelle au niveau du suivi. Je vois mon commercial une fois tous les 36 du mois, on a fait une fois un debrief avec le client, je lui envoie mon CRA à chaque fin de mois.
Je ne suis pas sur qu’il y ait une réelle différence d’état d’esprit entre un salarié de SSII et un freelance. Je pense que l’éthique que l’on a est quasiment la même. Je préviens toujours le plus en avance possible de mes congés, je ne renégocie pas mon tarif journalier tous les quatre matin (d’ailleurs je ne le ferais pas sur cette mission). Il me semble que les indépendants ont tendance à se former un peu plus, mais ce n’est pas une généralité non plus !
La question que l’on me pose souvent : et la paperasse ? Après un an, je l’attends toujours. Une partie des démarches a été faite en ligne. Pour la deuxième partie, j’ai pris un comptable qui me fait tout le reste (déclarations aux différents organismes, bilan) etc. Le seul point noir c’est la saisie des notes de frais, ca prend environ une heure par mois donc non, je ne croule pas sur la paperasse, en revanche, je paye mon comptable !
Les différences
Les avantages
L’aspect financier
Là où je vois la plus grosse différence c’est sur mes revenus. Comme je ne suis pas experte, je suis plutôt sur des missions longues avec peu d’inter-contrat. Mes revenus arrivent sous la forme d’indemnités mensuelles que je lisse (je me verse autant en inter-contrat / vacances / formation que quand je travaille tout le mois, on ne peut pas en dire autant du chiffre d’affaire de ma société). Ça me permet de ne pas avoir de ‘trou’ dans mon budget personnel. L’autre forme de revenu c’est les dividendes, que je ne toucherais qu’à la fin de l’année et qui seront plus ou moins conséquents en fonction du chiffre d’affaire fait ma société.
Il est vrai que l’on gagne beaucoup plus et qu’il faut prendre des assurances complémentaires (mutuelle, prévoyance par exemple) mais en réintégrant tous ses frais, je suis, hors dividende à un peu plus de 50% d’augmentation. Je ne parle pas des avantages CE ou en nature, je n’en ai jamais vraiment eu. Sur une année de 217 jours facturés, l’augmentation totale comprenant les dividendes atteint quasiment les 100%. Tout en gardant à l’esprit qu’en cas de tuile, on est vraiment beaucoup moins bien couverts que les salariés (pas d’indemnités journalières par exemple hors assurance prévoyance, pas de chômage dans la plupart des cas).
Les formations
L’un des autres avantages d’être indépendant, c’est de pouvoir au final payer un peu moins cher certaines formations (achat hors taxes et hors charges sociales) et de faire acheter par la société une partie de son matériel pro, ce n’est pas la panacée (c’est toujours à nous de remplir les caisses de l’entreprise) mais c’est toujours ça de gagner. J’ai une bibliothèque de plus en plus grande, je suis allée et je retournerai en 2010 à Devoxx, j’ai achetée un eee pc pour pouvoir rester connecter.
L’autonomie
Je trouve que les avantages que l’on a à être freelance, plus grande autonomie pour choisir ses missions, une meilleure gestion de l’intercontrat, pas de jours de congés à poser impérativement avant le 31 mai ou autre sympathie et la meilleure paye permette de compenser largement les quelques inconvénients.
Les inconvénients
Un inconvénient, et il est avéré, est que certains grands groupes ne veulent plus travailler avec des sous-traitants qui passent pars des SSII. Exit donc les indépendants de certaines missions ou alors passage obligé par un cabinet de broker. Les cabinets de broker sont spécialisés dans le placement des indépendants et en général, se font une marge entre 20% et 30% mais à ce que j’ai vu autour de moi, il y a un réel suivi et quelques services en plus. Enfin ça reste cher le service.
En cas de coup dur, effectivement, on est beaucoup moins protégés. Pas de chômage, pas d’indemnité journalière de base, la mutuelle est plus chère. Ce ne sont pas de réels inconvénients dans la mesure où comme on le sait avant, il suffit de mettre un peu de côté, on se fait soit même ses assurances. Pour la retraite, elle est en % plus faible mais comme on gagne plus, cela se vaut à peu près. Il me semble que l’on a pas non plus droit au congé parental (par contre des indemnités conséquentes pour le congé maternité et il existe également un congé paternité de 11 jours).
Les SSII où il fait bon de travailler
Un autre inconvénient est à prendre en considération quand on est mécontent de sa SSII. Certaines SSII n’apporteront rien de plus qu’une relation client-fournisseur. Mais ce n’est pas le cas de toute, il est possible d’intégrer des SSII qui font monter les compétences des collaborateurs de manière assez poussée. Avoir par exemple une journée de formation par mois ou envoyer ses collaborateurs à des formations, animer une communauté de développeur sont des points très appréciables de certaines SSII. En tant qu’indépendant, on est pas mal isolé, d’où l’importance de se réseauter et de participer à des évènements extérieurs (les Java User Group, les conférences diverses et variées…).
Les aspects commerciaux et contractuels.
Un autre inconvénient, c’est le fait de devoir se vendre. La négociation n’est pas une chose aisée et ce n’est pas naturel pour tous, c’est donc souvent délicat. En devenant indépendant, il faut donc apprendre à se vendre.
Il y a un point que j’ai négligé et sur lequel j’aurais pu me mordre les doigts c’est le contrat. Il faut vraiment que le contrat soit à 50/50. Il est possible de se faire accompagner par des juristes lors de la signature du contrat.
Je parle là d’une expérience de freelance en Java. Ce n’est pas la même chose sur d’autres langages. Il faut toujours se demander si son profil est facilement ‘vendable’ en fonction du marché avant de se lancer !
Sur un an, un bilan plus que positif. Ma situation n’a pas énormément changé quand je regarde mon travail quotidien chez mon client. En revanche, tout ce qui est extérieur ( ‘salaire’, formations, livres, … ) c’est amélioré.
]]>Pour ce faire, il existe plusieurs méthodes, l’utilisation de bouchon (‘stub’) ou de simulacre (‘mock’). L’article de référence est un article de Martin Fowler « Les simulacres ne sont pas des bouchons« . Pour résumer, une méthode bouchonnée est appelée sur un objet bouchon réel, centré sur le système testé. Il ne peut jamais faire échouer le test. On regarde l’état de l’objet final à la fin du test et non les étapes qui ont permis d’obtenir cet état. C’est un test basé sur des états.
En ce qui concerne les simulacres, les assertions ne portent pas sur l’objet final mais sur la manière dont ce dernier a été obtenu. C’est un test basé sur le comportement de la méthode. On peut contrôler le nombre de fois qu’une méthode a été invoquée, vérifier que ses paramètres correspondent bien entre ce qui est défini et ce qui est exécuté et faire échouer le test si l’enchaînement de méthodes ne correspond pas à l’enchaînement attendu par exemple.
Easymock utilise dans son fonctionnement le plus basique des simulacres, qui permettent de construire un test de manière très simple : l’ordre des méthodes invoquées, le nombre d’appel à une méthode peut engendrer un échec du test. Potentiellement, les tests sont plus fragiles et plus difficile à maintenir.
Mais EasyMock permet également la création de bouchons qui peuvent être réutilisé. Il est ainsi possible de maintenir des bouchons partagés entre différents tests unitaires, ce qui permet une meilleure maintenabilité. Dans ce cas, nous ne nous intéressons pas au comportement, uniquement au résultat.
La création de bouchon à l’aide de andStubReturn()
public Service getServiceMock() {
Service serviceMock = createMock(Service.class);
expect(serviceMock.appel1()).andStubReturn(Integer.valueOf(5));
expect(serviceMock.appel2(anyObject())).andStubReturn(BigDecimal.TEN);
replay(serviceMock);
}
La méthode andStubReturn signifie que cette méthode peut être appelée sans condition de nombre (0,1 …n) ni d’ordre. Il est simplement défini que si cette méthode est appelée, elle renverra un paramètre tel que défini via le andStubReturn. Il n’y a pas de verify(serviceMock) car les contrôles sur le comportement du mock ne nous intéressent pas.
La création de bouchon à l’aide des ‘niceMock’
Une autre possibilité lorsque l’on souhaite utiliser les bouchons (stub) est de créer un ‘nice mock’, qui est par défaut, renvoie 0, null ou false selon le paramètre de retour des méthodes :
myNiceMock = createNiceMock(Service.class);
Toujours sans utiliser de verify.
Les avantages du stub sont nombreux : les tests sont plus faciles à maintenir, il est possible de réutiliser les stubs au sein de plusieurs classes de tests… Néanmoins, il y a des situations où le test d’un comportement est plus adéquat que l’utilisation de bouchon comme par exemple, vérifier que certains paramètres sont bien calculés avant d’être envoyé à des services externes, ce qui est fréquemment mon cas.
]]> EasyMock est un framework de test qui peut dérouter dans un premier abord. Une fois qu’on a compris comment l’utiliser, on tombe sur un certain nombre d’erreurs qui reviennent très souvent et qui ne sont pas souvent explicites. Même si EasyMock 3.0 a clarifié un certain nombre d’erreurs, cet article (fait sous la 2.5.2) servira de pense-bête à ceux qui débutent avec ce framework.
EasyMock est un framework de test qui peut dérouter dans un premier abord. Une fois qu’on a compris comment l’utiliser, on tombe sur un certain nombre d’erreurs qui reviennent très souvent et qui ne sont pas souvent explicites. Même si EasyMock 3.0 a clarifié un certain nombre d’erreurs, cet article (fait sous la 2.5.2) servira de pense-bête à ceux qui débutent avec ce framework.
Les classes qui permettent de tester : une interface CalculService et son implémentation dont on cherche à tester unitairement les différentes méthodes. L’implémentation de CalculService fait appel à plusieurs méthodes de l’interface FormatService. Comme chacun des appels à la méthode FormatService est mocké, nous n’avons pas besoin de définir une implémentation correspondante.
package fr.java.freelance.service;
import java.math.BigDecimal;
public interface CalculService {
String calcul(BigDecimal a);
String calcul(BigDecimal a, BigDecimal b);
String calcul(String year, String month,
String day);
}
package fr.java.freelance.service.impl;
import java.math.BigDecimal;
import fr.java.freelance.service.CalculService;
import fr.java.freelance.service.FormatService;
public class CalculServiceImpl implements
CalculService {
private final FormatService formatService;
public CalculServiceImpl(
FormatService formatService) {
this.formatService = formatService;
}
public CalculServiceImpl() {
formatService=null;
}
public String calcul(BigDecimal a, BigDecimal b) {
return formatService.formatComplexe(a, b);
}
public String calcul(BigDecimal a) {
return formatService.formatSimple(a);
}
public String calcul(String year,
String month, String day) {
return formatService.formatSimple(year,
month, day);
}
}
package fr.java.freelance.service;
import java.math.BigDecimal;
public interface FormatService {
String formatSimple(BigDecimal a);
String formatComplexe(BigDecimal a,BigDecimal b);
String formatSimple(String year, String month,
String day);
}
Erreur 1 :Unexpected method call methodX(X)
java.lang.AssertionError:
Unexpected method call formatSimple(5):
at org.easymock.internal.MockInvocationHandler.invoke(MockInvocationHandler.java:43)
at org.easymock.internal.ObjectMethodsFilter.invoke(ObjectMethodsFilter.java:72)
at $Proxy5.formatSimple(Unknown Source)
@Test
public void testUnexpectedMethodCall() {
BigDecimal a = BigDecimal.valueOf(5);
BigDecimal b = BigDecimal.valueOf(5);
replay(formatServiceMock);
calculService.calcul(a);
verify(formatServiceMock);
}
Explication : La méthode formatSimple est appelée avec le paramètre 5 sans qu’elle ait été attendue.
Erreur 2 :methodA(A,B): expected: X, actual: Y
java.lang.AssertionError:
Expectation failure on verify:
formatComplexe(5, 5): expected: 1, actual: 0
at org.easymock.internal.MocksControl.verify(MocksControl.java:111)
at org.easymock.EasyMock.verify(EasyMock.java:1608)
@Test
public void testExpectedActual() {
BigDecimal a = BigDecimal.valueOf(5);
BigDecimal b = BigDecimal.valueOf(5);
expect(
formatServiceMock
.formatSimple(eq(BigDecimal
.valueOf(5)))).andReturn("XXX");
expect(
formatServiceMock
.formatComplexe(eq(BigDecimal
.valueOf(5)),eq(BigDecimal
.valueOf(5)))).andReturn("XXX");
replay(formatServiceMock);
calculService.calcul(a);
verify(formatServiceMock);
}
Explication : La méthode formatComplexe(5, 5) était attendue une fois (expected:1) et n’a jamais été appelée (actual:0)
Erreur 3 : X matchers expected, Y recorded
java.lang.IllegalStateException: 2 matchers expected, 1 recorded.
at org.easymock.internal.ExpectedInvocation.createMissingMatchers(ExpectedInvocation.java:56)
@Test
public void testExpectedRecorded() {
BigDecimal a = BigDecimal.valueOf(5);
BigDecimal b = BigDecimal.valueOf(6);
expect(
formatServiceMock
.formatComplexe(BigDecimal
.valueOf(5),eq(BigDecimal
.valueOf(6)))).andReturn("XXX");
replay(formatServiceMock);
calculService.calcul(a,b);
verify(formatServiceMock);
}
Il est interdit d’utiliser partiellement les comparateurs. Il faut les utiliser complètement ou pas du tout.
Ainsi
formatServiceMock.scale(BigDecimal .valueOf(5),eq(BigDecimal .valueOf(5)));
n’est pas OK (le deuxième argument utilise un comparateur, le premier la méthode equals => non OK).
formatServiceMock.scale(BigDecimal .valueOf(5),BigDecimal .valueOf(5));
OK
formatServiceMock.scale(eq(BigDecimal .valueOf(5)),eq(BigDecimal .valueOf(5)));
OK
Erreur 4 : Calling verify is not allowed in record state
java.lang.IllegalStateException: calling verify is not allowed in record state
at org.easymock.internal.MocksControl.verify(MocksControl.java:109)
at org.easymock.EasyMock.verify(EasyMock.java:1608)
@Test
public void testRecordState() {
BigDecimal a = BigDecimal.valueOf(5);
BigDecimal b = BigDecimal.valueOf(6);
expect(
formatServiceMock
.formatComplexe(eq(BigDecimal
.valueOf(5)),eq(BigDecimal
.valueOf(6)))).andReturn("XXX");
calculService.calcul(a,b);
verify(formatServiceMock);
}
Explication : un simple oubli du replay
Erreur 5 :missing behavior definition for the preceding method call
java.lang.IllegalStateException: missing behavior definition for the preceding method call formatComplexe(5, 6)
at org.easymock.internal.MocksControl.replay(MocksControl.java:101)
at org.easymock.EasyMock.replay(EasyMock.java:1540)
@Test
public void testMissingBehavior() {
BigDecimal a = BigDecimal.valueOf(5);
BigDecimal b = BigDecimal.valueOf(6);
formatServiceMock
.formatComplexe(eq(BigDecimal
.valueOf(5)),eq(BigDecimal
.valueOf(6)));
replay(formatServiceMock);
calculService.calcul(a,b);
verify(formatServiceMock);
}
Explication : La méthode formatServiceMock.formatComplexe(BigDecimal a,BigDecimal b) renvoie un paramètre. Il faut donc indiquer quel paramètre de retour cette dernière doit renvoyée via la méthode expect et le andReturn. Dans ce cas, l’écriture correcte est :
expect(
formatServiceMock
.formatComplexe(eq(BigDecimal
.valueOf(5)),eq(BigDecimal
.valueOf(6)))).andReturn("XXX");
Erreur 6 : NullPointerException
@Test
public void testNullPointer() {
BigDecimal a = BigDecimal.valueOf(5);
BigDecimal b = BigDecimal.valueOf(6);
formatServiceMock
.formatComplexe(eq(BigDecimal
.valueOf(5)),eq(BigDecimal
.valueOf(6)));
replay(formatServiceMock);
calculServiceDouble.calcul(a,b);
verify(formatServiceMock);
}
avec
@Before
public void before() {
formatServiceMock = createMock(FormatService.class);
calculService = new CalculServiceImpl(
formatServiceMock);
calculServiceDouble = new CalculServiceImpl();
}
Explication : Dans 90% des cas, le mock n’a pas été affecté au service testé.
Le code source est dispo ici https://code.google.com/p/easymock-error/
]]>
Il y a différentes possibilités :
- S’abonner à la mailing list de son « Java User Group » local
- suivre les flux des différentes SSII proches de chez vous qui organisent de temps à autres des soirées.
- Twitter est également un bon moyen de se tenir à jour !
- L’équipe de JDuchess France fournit également un calendrier des évènements à venir : Agenda Conférences des Duchess. Il est possible d’ajouter facilement cet agenda à son Google calendar en tant qu’agenda ami : Consulter l’agenda Conférences dans Google Agenda
Si vous désirez ajouter un de vos évènements à l’agenda des JDuchess, tout est indiqué sur le blog des duchess
- 1/3 des missions sont pourvues sans qu’il y ait d’appel d’offre ou pourvues avant même la parution de l’AO (Copinage…). Sans copains, moins d’opportunités.
- Tous les grands comptes ont un service achat qui référence les fournisseurs. En étant indépendant, impossible d’obtenir de référencement. Nous sommes obligé de passer par un intermédiaire qui se sert largement au passage (20% en règle générale).
- Aucun pouvoir de négociation face à nos propres fournisseurs. Nous payons nos formations plein pot, nos conférences pleins pot et nos comptables pleins pot
- Pas de support en cas de difficulté technique, commerciale ou même juridique en mission.
- Pas d’image. Nous avons même plutôt une image « négative », certains nous voient comme des mercenaires.
- Si vous êtes formateur, ou désirez donner des formations, difficile de proposer un catalogue de formations et de se faire connaître et en restant isolé.
Ce rassembler autour d’une structure commune devrait permettre de palier à toutes ces difficultés, c’est ce que propose Prosymna.
Prosymna
Le Groupement d’Intérêt Économique (GIE) Prosymna (prononcer ProSSimna et non ProZimna) est l’initiative de deux indépendants, Nicolas Ludmann et Pierre Stevenin. L’idée est simple : créer un « Cabinet de conseil » sous la forme d’un GIE composé exclusivement d’indépendants.
L’objectif du GIE est de favoriser le développement de l’activité de chaque adhérent par 3 leviers :
- L’amélioration de la démarche commerciale
- La réduction des coûts de fonctionnement
- La mise en commun des retours d’expériences et des savoirs-faire

Le tout sans ingérences. Chaque société reste complètement libre. Les contrats se font en direct avec les clients et le GIE n’intervient en tant qu’intermédiaire qu’exceptionnellement lorsque la contractualisation directe est impossible. Dans ce cas 2% de la facturation est prélevée (à comparer avec les 20% habituel).
Amélioration de la démarches commerciale
Il s’agit de permettre :
- L’obtention de référencement et la réponse aux appels d’offres en mettant en avant le Chiffre d’Affaire et la taille global du GIE aux clients finaux.
- D’avoir une image, celle du GIE. On peut imaginer sponsoriser des conférences ou en proposer sur nos domaines d’expertise.
- La mise en commun de support commerciaux : site Internet, e-mail, contrat type, modèle de CV etc.
- La mise en avant de l’ensemble des références clients
- Le plus important à mon avis : La création d’un réseau d’apporteurs d’affaires. Nous avons tous notre « petit » réseau de « clients décideurs » que nous pourrons ainsi utiliser pour faire des affaires au sein du GIE, en plaçant les autres membres du GIE.
Il s’agirait également de faire du GIE un centre de formation, de mettre en commun les accréditations, les locaux et tout simplement l’offre de formations.
Partage du savoir
Il s’agit cette fois de :
- Créer un espace documentaire : Je suis plus que perplexe sur ce point, je trouve ce principe simplement dépassé avec toutes les sources d’informations, les forums spécialisés que l’on trouve sur Internet, une espace documentaire ne pourra pas rivaliser et sera certainement du temps perdus. En revanche, un blog aurait beaucoup d’intérêt.
- Créer un réseau de professionnels à qui l’on pourrait faire appel pour du support lors d’une difficulté ou d’un besoin spécifique en mission mais également pour répondre à des appels d’offres nécessitant plusieurs personnes.
- Mettre en place des journées de partage de connaissances comme le font Zenika, Xebia, ou SFEIR…
Réductions des coût fournisseurs
La phrase choc fut : « Présenter 4 personnes pour une formation permet d’obtenir 40% de réduction sans effort ». Lorsque l’on connaît le prix des formations ce simple avantage justifie à lui seul la création d’un groupement.
Mais le spectre est large, il y a les comptables mais aussi les banques et les affactureurs qui ne traitent pas du tout de la même façon une structure qui fait 100k€ de CA et une structure qui fait 10 millions de CA.
Prosymna fournira également une domiciliation dans Paris avec possibilité de louer des locaux.
Domaine d’activité
Prosymna vise le conseil au sens large : organisation et management, gestion de projets, gestion de processus, maîtrise d’oeuvre, maîtrise d’ouvrage. Au forfait ou en régie. N’y a t’il pas un risque à viser trop large ? Comment se vendre « Cabinet d’expert » si le GIE est multi compétences ?

Une solution serait de créer une seule structure mais plusieurs pôles avec une marque différente pour chaque pôle. Si le GIE atteint les 100 adhérents nous pouvons facilement imaginer 4 pôles de 25 personnes dont un pôle « Java » rien qu’à nous ! Face aux clients nous serions un cabinet d’expert de 25 personnes et face aux fournisseurs nous serions toujours un regroupement de 100 sociétés.
Organisation du GIE
La première chose à savoir sur les GIE c’est qu’il est impossible pour un GIE de faire des bénéfices ou des pertes. Les membres sont tous solidaires des dettes et créances du GIE. Cela à un coté intéressant au niveau des créances, car si le montant des adhésions n’est pas consommé il sera possible de réduire, voir de rembourser une partie des cotisations payées. A contrario, cela présente également un risque si le GIE s’endette. Ce risque est à modérer puisque par définition, nous n’avons pas beaucoup de fournisseurs, aucun salarié et nos marges sont très importantes. De plus le GIE ne contractera qu’exceptionnellement et refusera de le faire pour des missions « à risque ». Par exemple, les missions de type conduite du changement où les décisions du prestataire peuvent coûter très chère et engager sa responsabilité seront étudiées de manière collégiale. Pour en finir avec le risque, il est tout à fait possible de proposer un contrat de prestation avec des clauses limitant la responsabilité du GIE à hauteur des sommes prises en charges par l’assurance.
Adhésion
L’adhésion est limitée aux personnes morales. Pas d’Entreprise individuelles ou d’auto-entrepreneur.
L’adhésion d’un nouveau membre est soumise aux votes des membres en assemblée générale.
Pour éviter les profiteurs, qui ne viendraient que pour trouver une mission et repartiraient immédiatement, la sortie du GIE ne pourra se faire que dans un délai de 6 mois.
Prosymna propose 2 niveaux d’adhésion et 3 niveaux que je qualifierai « d’investissement dans le GIE »
- Les adhérents en industrie : C’est le statut de base, ils n’apportent que leur savoir-faire.
- Les adhérents en capital : Ce sont les adhérents qui ont au moins un an d’ancienneté au sein du GIE et qui souhaitent s’investir plus en apportant du capital.
- Le conseil d’administration : Il est obligatoire en GIE et sera donc tenu par les adhérents en capital qui souhaitent s’investir fortement dans le GIE. C’est l’organe exécutif de la structure.
Afin de garantir une complète transparence, des contre-pouvoirs seront mis en place :
- Un contrôle de la gestion du Conseil d’administration par un membre non administrateur.
- La nomination d’un contrôleur des comptes indépendant du GIE (un 2ème comptable en fait).
- Les comptes seront mis à disposition de tous les membres souhaitant y avoir accès.
Droits de votes
Les décisions importantes (adhésions, exclusions, modifications des statuts) sont prises en assemblées générales.
- Une part = 1 vote.
- 50% des parts sont détenus en capital
- 50% des parts sont détenus en industrie.
Là ça se complique. Je donne un exemple :
- Le capital représente 50 000€
- L’apport en industrie représente 50 personnes.
Comme il doit y avoir autant de part en industrie qu’en capital, le capital aura 50 votes et l’industrie 50 votes.
- Avec Mathilde nous sommes 2 personnes, nous avons donc 2 parts en industrie et 2 votes.
- Un des administrateur à apporté 3000€, il a donc 3 parts en capital plus 1 part en industrie : 4 votes.
Financement
J’aime bien le financement proposé. C’est un système juste, à la française, inspiré de notre système d’impôt sur le revenu. Plus on est « riche » et plus on va participer de manière importante à l’effort de financement.

Pour que cela soit plus parlant, je vais encore une fois donner un exemple. Une société qui fait 100k€ de chiffre d’affaire va cotiser :
- 500€ lors de l’adhésion
- puis 1000€ annuellement en 4 versements trimestriel de 250€
Cela peut paraître élevé mais si cela peux être remboursé 10 fois si le GIE nous permet de contracter en direct et de faire 110k€ ou 120k€ de CA au lieu de 100k€. Une formation de 3000€ pourra ne coûter que 2000€, un apport d’affaire remboursera également une ou 2 années de cotisations etc. Chacun fera ses petits calculs et verra son intérêt à adhérer ( ou à ne pas adhérer ).
Ce qui risque de bloquer les adhésions, c’est que les adhérents potentiels étant déjà en mission, ayant déjà leurs fournisseurs et leur réseau, ils n’auront pas le besoin immédiat de cette structure et risquent de repousser à plus tard l’adhésion pour ne finalement jamais adhérer (et plouf!). Je me demande si, plutôt que de faire une adhésion à 500€ il ne serait pas mieux de faire l’inverse, avec 6 mois de dispense de cotisations, au moins le temps d’atteindre une taille critique. En contrepartie, je porterai une grande attention à la sélection des premiers adhérents.
Le mot de la fin
La présentation du GIE s’est terminée par un « Plan d’action » sur l’année 2010 et sur les objectifs à 4 ans. Cela m’a fait sourire car je suis entrain de lire l’excellent livre Rework qui explique justement que ce n’est que perte de temps de faire des plans sur la comète. L’idée du GIE est excellente, cela fait plusieurs mois que j’ai également eu cette idée tout en ayant ni le courage ni les capacités d’en être l’initiateur. Cette opportunité doit être soit saisie soit être source d’inspiration mais je pense que pour Prosymna il faut maintenant dépenser l’énergie à bâtir une base solide.
Nous avons également évoqué durant la réunion le positionnement du GIE face à la chasse aux indépendants actuellement ouverte chez certains grands comptes.
Si vous voulez en savoir plus, je vous invite à vous inscrire à la prochaine réunion qui aura lieu Mardi 8 Juin 2010. Les inscriptions se font ici.
Être freelance présente beaucoup d’avantages pour très peu d’inconvénient. On peut toutefois faire l’exercice de les lister :
- 1/3 des missions sont pourvus sans qu’il y ait d’appel d’offre ou pourvues avant même la parution de l’AO (Copinage…). Sans copains, moins d’opportunités.
- Tous les grands comptes ont un service achat qui référence les fournisseurs. En étant indépendant, impossible d’obtenir de référencement. Nous sommes obligé de passer par un intermédiaire qui se sert largement au passage (20% en règle générale).
- Aucun pouvoir de négociation fasse à nos propres fournisseurs. Nous payons nos formations plein pôt, nos conférences pleins pôt et nos comptables pleins pôt
- Pas de support en cas de difficulté technique, commerciale ou même juridique en mission.
- Pas d’image. Nous avons même plutôt une image « négative », certains nous voit comme des mercenaires..
- Si vous êtes formateur, ou désirez donner des formations, difficile de proposer un catalogue de formations et de se faire connaître et en restant isolé.
Ce rassembler autour d’une structure commune devrait permettre de palier à toutes ces difficultés, c’est ce que propose Prosymna.
Prosymna
Le Groupement d’Intérêt Économique (GIE) Prosymna (prononcer ProSSimna et non ProZimna) est l’initiative de deux indépendants, Nicolas Ludmann et Pierre Stevenin. L’idée est simple : créer un « Cabinet de conseil » sous la forme d’un GIE composé exclusivement d’indépendant en société.
L’objectif du GIE est de favoriser le développement de l’activité de chaque adhérent par 3 leviers :
- L’amélioration de la démarche commerciale
- La réduction des coûts de fonctionnement
- La mise en commun des retours d’expériences et des savoirs-faires
Le tout sans ingérences. Chaque société reste complétement libre. Les contrats se font en direct avec les clients et le GIE n’intervient en tant qu’intermédiaire qu’exceptionnellement lorsque la contractualisation directe est impossible. Dans ce cas 2% de la facturation est prélevée (à comparer avec les 20% habituel).
Amélioration de la démarches commerciale
Il s’agit de permettre :
- L’obtention de référencement et la réponse aux appels d’offres importante en mettant en avant le Chiffre d’Affaire et la taille global du GIE aux clients finaux.
- D’avoir une image, celle du GIE. Pour cela, il serait possible de sponsoriser de grands évènements comme les JUGs ou d’autres conférences.
- La mise en commun de support commerciaux : site internet, e-mail, contrat type, modèle de CV, et logo.
- La mise en avant de l’ensemble de nos références clients
- Le plus important à mon avis : La création d’un réseau d’apporteurs d’affaires. Nous avons tous notre « petit » réseau de décideurs que nous pourrons ainsi utiliser pour faire des affaires au sein du GIE, en plaçant les autres membres du GIE.
Il s’agirait également de faire du GIE un centre de formation, de mettre en commun les accréditations, les locaux et tout simplement l’offre de formations.
Partage du savoir
Il s’agit cette fois de :
- Créer un espace documentaire : Je suis plus que perplexe sur ce point, je trouve ce principe simplement dépassé avec toutes les sources d’informations, les forums spécialisé que l’on trouve sur Internet, une espace documentaire ne pourra pas rivaliser et sera certainement du temps de perdue. En revanche, un blog à beaucoup d’intérêt.
- Créer un réseau de professionnels à qui l’on pourrait faire appel pour du support lors d’une difficulté ou d’un besoin spécifique en mission mais également pour répondre à des appels d’offres commune, nécessitant plusieurs personnes.
- Mettre en place des journées de partage de connaissances comme le font Zenika, Xebia, ou SFEIR…
Réductions des coût fournisseurs
La phrase choc fut : « Présenter 4 personnes pour une formation permet d’obtenir 40% de réduction sans effort ». Lorsque l’on connaît le prix des formations ce simple avantage justifie à lui seul la création d’un groupement.
Mais le spectre est plus large, il y a les comptables mais aussi les banques et les affactureurs qui ne traitent pas du tout de la même façon une structure qui fait 100k€ de CA et une structure qui fait 10 millions de CA. Prosymna fournira également une domiciliation dans Paris avec possibilité de louer des locaux.
Domaine d’activité
Prosymna vise le conseil au sens large : organisation et management, gestion de projets, gestion de processus, maîtrise d’oeuvre, maîtrise d’ouvrage. Au forfait ou en régie. N’y a t’il pas un risque à viser trop large ? Comment se vendre « Cabinet d’expert » si le GIE est multi-compétences ?
Un solution serait de créer une seule structure mais plusieurs pôles avec une marque différente pour chaque pôle. Si le GIE atteint les 100 adhérents nous pouvons facilement imaginer 4 pôles de 25 personnes dont un pôle « Java » rien qu’à nous ! Fasse aux clients nous serions un cabinet d’expert de 25 personnes et fasse aux fournisseurs nous serions toujours un regroupement de 100 sociétés.
Organisation du GIE
Le première chose à savoir sur les GIE c’est qu’ il est impossible pour un GIE de faire des bénéfices ou des pertes. Les membres sont tous solidaires des dettes et créances du GIE. Cela à un coté intéressant au niveau des créances, car si le montant des adhésions n’est pas consommé il sera possible de réduire, voir de rembourser une partie des cotisations payées. A contrario, cela présente également un risque si le GIE s’endette. Ce risque est à modérer puisque par définition, nous n’avons pas beaucoup de fournisseurs, aucun salarié et nos marges sont très importantes. De plus le GIE ne contractera qu’exceptionnellement et refusera de le faire pour des missions « à risque ». Par exemple, les missions de type conduite du changement où les décisions du prestataires peuvent coûter très chère et engager sa responsabilité seront étudiée de manière collégiale. Pour en finir avec le risque, il est tout à fait possible de proposer un contrat de prestation avec des clauses limitant la responsabilité du GIE à hauteur des sommes prises en charges par l’assurance.
Adhésion
L’adhésion est limité aux personnes morales. Pas d’Entreprise individuelles ou d’auto-entrepreneur.
L’adhésion d’un nouveau membre est soumise aux votes des membres en assemblée générale.
Pour éviter les profiteurs, qui ne viendrait que pour trouver une mission et repartirai immédiatement, la sortie du GIE ne pourra se faire que dans un délai de 6 mois.
Prosymna propose 2 niveaux d’adhésion et 3 niveaux que je qualifierai « d’investissement dans le GIE »
- Les adhérents en industrie : C’est le statut de base, ils n’apportent que leur savoir-faire.
- Les adhérents en capital : Ce sont les adhérents qui ont une certaine anciennté au sein du GIE et qui ont souhaités s’investir encore plus dans en apportant du capital.
- Le conseil d’administration : Il est obligatoire en GIE et sera donc tenu par les adhérents en capital qui souhaitent s’investir fortement dans le GIE. C’est l’organe exécutif de la structure.
Afin de garantir un complète transparence, des contres-pouvoirs seront mis en place :
- Un contrôle de la gestion du Conseil d’administration par un membre non administrateur.
- La nomination d’un contrôleur des comptes indépendant du GIE (un 2ème comptable en fait).
Droits de votes
Les décisions importantes (adhésions, exclusions, modifications des statuts) sont prises en assemblés générales.
- Une part = 1 vote.
- 50% des parts sont détenus en capital
- 50% des parts sont détenus en industrie.
Là ça se complique. Je donne un exemple :
- Le capital représente 50 000€
- L’apport en industrie représente 50 personnes.
Comme il doit y avoir autant de part en industrie qu’en capital, le capital aura 50 votes et l’industrie 50 votes.
- Avec Mathilde nous sommes 2 personnes, nous avons donc 2 parts en industrie et 2 votes.
- Un des administrateur à apporté 3000€, il a donc 3 parts en capital plus 1 part en industrie : 4 votes.
Financement
J’aime bien le financement proposé. C’est un système juste, à la française, inspiré de notre système d’impôt sur le revenus. Plus est riches et plus on va participer de manière importante à l’effort.
Pour que cela soit plus parlant, je vais encore une fois donner un exemple. Une société qui fait 100ke de chiffre d’affaire va cotiser :
- 500€ lors de l’adhésion
- puis 1000€ annuellement en 4 versements trimestriel de 250€
cela peut paraître élevé mais si cela peux être remboursé 10 fois par an si le GIE nous permet de contracter en direct et de faire 110k€ ou 120k€ de CA au lieu de 100k€. Une formation de 3000€ pourra ne couter que 2000€, un apport d’affaire remboursera également une ou 2 années de cotisations etc. Chacun fera ses petits calculs et verra son interêt a adhérer ( ou à ne pas adhérer ).
Ce qui risque d’en dissuader plus d’un à mon humble avis, c’est qu’en étant déjà en mission, en ayant déjà nos fournisseurs, notre réseau, nous n’ayons pas un besoin immédiat de cette structure et de repousser à plus tard l’adhésion pour ne finalement pas adhérer (et plouf!). Honnêtement, à leur place, plutôt que de faire une adhésion a 500€ je ferai l’inverse, avec 6 mois de dispense de cotisations et pas d’adhésion, au moins le temps d’atteindre une taille critique. En contrepartie, je porterai une grande attention à la sélection des premiers adhérents.
Le mot de la fin
La présentation du GIE s’est terminée par un « Plan d’action » sur l’année 2010 et sur les objectifs à 4 ans. Cela m’a fait sourire car je suis entrain de lire l’excellent livre Rework qui explique justement que ce n’est que perte de temps de faire des plans sur la comète. L’idée du GIE est excellente, je pense qu’il faut maintenant dépenser l’énergie à bâtir une base solide.
Nous avons également évoqué durant la réunion le positionnement du GIE fasse à la chasse aux indépendants actuellement ouverte chez certain grand compte.
Si vous voulez en savoir plus, je vous invite à vous inscrire à la prochaine réunion qui aura lieu Mardi 8 Juin 2010. Les inscriptions se font ici.
en première partie No SQL pour les entreprises / TDD et ATDD / HTML 5 et en deuxième User Experience / Les nouveaux frameworks web (Play! Vaadin) / Les commentaires dans le code . Et d’autres que j’ai oublié !
J’ai participé à TDD/ATTD et à la session sur les commentaires dans le code.
TDD – ATTD
Le Test Driven Development est une méthode de programmation basée sur les règles suivantes :
- on écrit un test
- on vérifie qu’il échoue
- on écrit juste ce qu’il faut pour que le test passe (et rien d’autre!)
- on vérifie qu’il passe
- on refactorise encore et encore
L’Acceptance Test Driven Development (ATDD) est basée sur l’idée de faire des tests d’acceptance (automatisés) avant même de commencer les développements. La bonne mise en pratique se fait en deux temps : le client, les utilisateurs, la MOA écrit les test pendant que les développeurs se chargent de les automatiser. Plusieurs outils existent pour cela comme par exemple Greenpepper, Fit/Fitnesse, Robot Framework … La plupart se base sur des wiki pour permettre aux personnes fonctionnelles d’écrire facilement leurs tests.
Dans une approche basée sur l’ATDD, les spécifications et les implémentations sont dirigées par des exemples concrets. Décrire précisément des cas de tests oblige celui qui spécifie à aller plus loin que les spécifications habituelles. Cette méthode a également l’avantage d’être plus claire pour le développeur.
Le TDD
Peu de personnes font du TDD pur et dur, la plupart de la dizaine de personnes présentes écrivent un bout de code avant de tester. Néanmoins, la personne ayant le plus d’expérience est un adepte du TDD pur et dur depuis de nombreuses années. Les frameworks de mocks permettent de simplifier sensiblement la tâche du développeur. Néanmoins, le TDD est loin d’être une évidence pour tout le monde. Le risque de perdre de vue l’architecture générale du projet, la difficulté de la sensibilisation d’une équipe aux tests, les problèmes de maintenabilité et de refactoring sont quelques uns des exemples soulevés pour montrer les difficultés engendrés par l’application de cette méthode.
L’ATDD
Au niveau des tests d’acceptance, seul une seule personne les utilise dans un contexte d’entreprise.
Le gros problème soulevé par les tests d’acceptance c’est la difficulté, lors d’utilisation d’outils type fit/fitness greenpepper est la refactorisation des tests : les tests écrits sont difficilement maintenable dans le temps. L’ATDD permet au développeur d’avoir des spécifications claires et précises, permettant entre autre de réduire les difficultés de communication entre la maitrîse d’oeuvre et d’ouvrage. Un autre point bloquant est que l’ATDD demande à l’équipe fonctionnelle de s’impliquer et de se former à un nouvel outil, ce qui n’est pas simple dans certains contextes.
Digressions diverses
Un autre aspect négatif est le temps pris par les tests, qu’ils soient d’intégration, d’acceptance … Ils ont tendance à grossir encore et encore, à devenir de moins en moins maintenables jusqu’à devenir contre productif. Plutôt qu’un enchaînement d’action, difficile maintenable dans le temps, il faut se focaliser sur les work flows et sur les règles business. Il faut également essayer de limiter quand cela est possible l’utilisation de l’IHM dans les tests d’acceptance.
Les commentaires dans le code
Olivier Croisier a pour projet de synthétiser les bonnes pratiques de commentaires. Plusieurs points ont été abordés dans cet atelier.
Au niveau des APIs publics, la javadoc est coûteuse à maintenir mais obligatoire, et en anglais. Lorsqu’il y a du code, il est souvent obsolète donc à utiliser avec précaution.
Au niveau du code non public, les personnes présentes utilisent beaucoup moins la javadoc. On remarque souvent qu’il n’y en a pas, qu’elle est obsolète ou inintéressante. Un point pour commenter facilement le code est l’encapsulation du code dans des méthodes private qui, via leurs noms, sont auto-documentées. On peut donc alors comprendre facilement une méthode principale en lisant la succession de méthodes appelées. A noter qu’il ne suffit pas de découper son code n’importe comment, il est important de ne pas avoir une profondeur d’appels de méthodes de ce type trop importantes (A qui appelle B qui appelle C qui appelle D qui appelle E). Un moyen de découper convenablement le code est d’éviter d’appeler dans la méthode principale des méthodes fonctionnelles et des méthodes techniques. Le code est plus lisible si on découpe du fonctionnel vers le technique.
J’ai utilisé cette méthode pour découper des classes de plusieurs centaines de lignes avec un fonctionnel un peu compliqué et je trouve que le code est beaucoup plus clair, en cas d’évolution ou de recherche d’un bug, on sait directement où aller. Le problème de cette méthode est que parfois, on ne voit pas certains refactoring qui pourrait faire gagner en lisibilité (là encore, il est possible de perdre de vue la ‘big picture’). C’est pour cette raison que certains estiment qu’une méthode n’a d’utilité que lorsqu’elle est réutilisée et que les méthodes de plusieurs dizaines de lignes sont en fait plus claires. Sur ce sujet, lire Clean Code et Effective Java est essentiel.
Un autre point est l’utilisation des commentaires du style /**** GETTERS AND SETTERS *****/ /***** CONSTRUCTORS *****/ . La encore, cette méthode ne fait pas l’unanimité (et je suis loin d’en être la première fan).
Au niveau de l’utilisation français/anglais, c’est assez mitigé. La plupart écrivent leurs noms de variables et de commentaires en anglais, d’autres se permettent quelques écarts en français et pour quelques un le français est la norme.
Au niveau des tâches (//FIXME //XXX //TODO), la plupart des personnes présentes sont d’accord avec le fait que cela n’est utile que si la tâche nous concerne.
En ce qui concerne les warnings sur les classes, l’idée est d’en avoir aucun : l’utilisation des outils comme PMD, FindBugs, CheckStyle est à bien configurer avant utilisation, car la multiplication des warnings noie les vrais warnings dans de la pollution.
Je retiens également que Implementation Patterns de Kent Beck sera une de mes lectures estivales et que l’outil mvn eclipse:eclipse permet de faire bien plus de choses que prévues !
J’ai passé un agréable moment, j’y étais venue surtout par curiosité et je compte bien retourner à la prochaine ! Ça a duré jusqu’à un peu plus de 23 heures pour moi, ce qui fait quand même une bonne soirée. Énormément de digressions, ça part dans tous les sens mais c’est souvent là que c’est le plus intéressant !
Sur twitter : http://twitter.com/KawaCampParis
]]>expect(maMethode("XYZ","BZT")).andReturn("XXX")
// est correct tout comme :
expect(maMethode((String)anyObject(),eq("BZT"))).andReturn("XXX")
// mais pas :
expect(maMethode((String)anyObject(),"BZT")).andReturn("XXX")
Sauf que mon erreur du jour, c’est que cette expression arrive sur la méthode :
« expect(formatServiceMock.scale(eq(BigDecimal.valueOf(10)))).andReturn(c) » qui elle est correcte a première vue.
Le test passe unitairement dans Eclipse et dans Surefire. L’ensemble des tests passent dans Eclipse, il n’y a que dans lors de la tâche « install » de Maven que l’erreur se produit (et non, Maven n’a rien à voir là dedans :p).
Si on zoome sur le code simplifié au maximum, on obtient :
Une classe et son interface, FormatServiceImpl et FormatService qui ne contiennent que 2 méthodes vides
public class FormatServiceImpl implements
FormatService {
private static final int SCALE = 5;
public void scale(BigDecimal a) {
}
public void scale2(BigDecimal a) {
}
Une classe et son interface, « CalculServiceImpl » et « CalculService » qui contient une méthode et un champ privé de type « FormatService ».
public class FormatServiceImpl implements
public class CalculServiceImpl implements
CalculService {
private final FormatService formatService;
public CalculServiceImpl(
FormatService formatService) {
this.formatService = formatService;
}
public BigDecimal addAndscale(BigDecimal a,
BigDecimal b) {
formatService.scale(a.add(b));
return a.add(b);
}
}
La classe de test de « CalculServiceImpl » contient une méthode de test « testAddAndScale » qui pose problème uniquement dans le cas d’une exécution des tests via Surefire, le plugin Maven.
public class CalculServiceImplTest {
private CalculServiceImpl calculService;
private FormatService formatServiceMock;
@Before
public void before() {
formatServiceMock = createMock(FormatService.class);
calculService = new CalculServiceImpl(
formatServiceMock);
}
@Test
public void testAdd() {
BigDecimal a = BigDecimal.valueOf(5);
BigDecimal b = BigDecimal.valueOf(5);
BigDecimal c = BigDecimal.valueOf(10);
formatServiceMock.scale(eq(BigDecimal
.valueOf(10)));
replay(formatServiceMock);
assertEquals(c, calculService.addAndscale(a,
b));
verify(formatServiceMock);
}
Le fonctionnement de cette classe est classique : on définit un mock, ici : « formatServiceMock » que l’on affecte à l’implémentation testée calculService. On lui affecte un comportement spécifique : la méthode « scale » de « FormatService » est appelée avec le paramètre équivalent à « BigDecimal.valueOf(10) ». Le mock est ensuite chargée avec la méthode « replay(formatServiceMock) ».
L’action testée est ensuite lancée : « calculService.addAndscale(a,b) » que l’on vérifie être égale à « c ». Puis avec : « verify(formatServiceMock) », on vérifie que le « mock formatServiceMock » a bien eu le comportement attendu c’est à dire que la méthode « scale » de « FormatService » a bien été appelée avec le paramètre équivalent à BigDecimal.valueOf(10) .
Cette classe de test ne soulève une erreur que lorsqu’elle est appelé via les test Surefire de Maven. Si on la lance unitairement via Eclipse (Run as Junit test) ou via Maven sSurefire individuellement (via mvn -Dtest=CalculServiceImplTest test) aucun problème. Si on lance l’ensemble des tests unitaires via Eclipse (Run as JUnit test) idem aucun problème.
Par contre, si on la lance avec l’ensemble des tests Surefire, on obtient l’erreur :
java.lang.IllegalStateException: 1 matchers expected, 2 recorded. at org.easymock.internal.ExpectedInvocation.createMissingMatchers(ExpectedInvocation.java:56) at org.easymock.internal.ExpectedInvocation.<init>(ExpectedInvocation.java:48) at org.easymock.internal.ExpectedInvocation.<init>(ExpectedInvocation.java:40) at org.easymock.internal.RecordState.invoke(RecordState.java:76) at org.easymock.internal.MockInvocationHandler.invoke(MockInvocationHandler.java:38) at org.easymock.internal.ObjectMethodsFilter.invoke(ObjectMethodsFilter.java:72) at $Proxy5.scale(Unknown Source) at fr.java.freelance.easymock.CalculServiceTest.testAdd(CalculServiceTest.java:40)
Impossible dans un premier temps de voir d’où vient l’erreur. On utilise alors le système permettant de débugger les tests à distance à l’aide de : « mvn -Dmaven.surefire.debug test ». Lorsque l’on lance la commande, l’exécution se met en pause tant qu’elle n’a pas reçu de connexion sur son port 5005 (en configuration par défaut, customizable).
[INFO] Scanning for projects... [INFO] ------------------------------------------------------------------------ [INFO] Building EasyMockTest [INFO] [INFO] Id: fr.java.freelance:TestSpringPath:jar:0.0.1-SNAPSHOT [INFO] task-segment: [test] [INFO] ------------------------------------------------------------------------ [INFO] [resources:resources] [INFO] Using default encoding to copy filtered resources. [INFO] [compiler:compile] [INFO] Nothing to compile - all classes are up to date [INFO] [resources:testResources] [INFO] Using default encoding to copy filtered resources. [INFO] [compiler:testCompile] [INFO] Nothing to compile - all classes are up to date [INFO] [surefire:test] [INFO] Surefire report directory: E:\workspace\EasyMock\target\surefire-reports Listening for transport dt_socket at address: 5005
Il suffit alors dans Eclipse d’aller dans le mode Debug Configurations et de créer une remote application sur le port 5005 et on peut débugger le test dans Eclipse .
Un moyen de voir le nombre d’objet enregistré dans EasyMock est de mettre un point d’arrêt juste avant la levée de l’exception : la méthode mockée doit avoir autant d’arguments que la liste enregistrée. Ici, la méthode est appelée avec un argument (on ne se formalise pas sur le null, seul compte ici le nombre d’argument) alors que la liste en possède 2 : un matcher « Any » et un matcher « Equals », d’où le « IllegalStateException ».
Cliquer pour voir en grand :

La recherche pour savoir d’où provient le « Any » est assez fastidieuse (le « Equals » étant celui du test). Les objets enregistrés le sont via un autre chemin et partagés via l’objet « LastControl ». Pour comprendre comment les matchers sont enregistrés, il suffit de faire un pas à pas en mode debug.
Si on entre (via F5) dans le détail de l’appel à « formatServiceMock.scale(eq(BigDecimal
.valueOf(10))); », on arrive tout d’abord sur le calcul du « valueOf » puis sur la méthode « eq » de la classe EasyMock :
public static <T> T eq(T value) {
reportMatcher(new Equals(value));
return null;
}
On entre à nouveau dans « reportMatcher(new Equals(value)); »
En continuant un peu avec F5 on arrive à dans la classe « EasyMock » :
/**
* Reports an argument matcher. This method is needed to define own argument
* matchers. For details, see the EasyMock documentation.
*
* @param matcher
*/
public static void reportMatcher(IArgumentMatcher matcher) {
LastControl.reportMatcher(matcher);
}
On continue à regarder ce qui se passe dans « LastControl ». On arrive sur une classe contenant plusieurs threads : « threadToControl » – « threadToCurrentInvocation » – « threadToArgumentMatcherStack ». Celui qui nous intéresse est « threadToArgumentMatcherStack ». Il contient une pile d’ « ArgumentMatcher ».Le « reportMatcher » permet d’ajouter chacun des matchers pour chacun des arguments. A cet étape là du calcul, cette pile doit être vide.
public static void reportMatcher(IArgumentMatcher matcher) {
Stack stack = threadToArgumentMatcherStack.get();
if (stack == null) {
stack = new Stack();
threadToArgumentMatcherStack.set(stack);
}
stack.push(matcher);
}

Comme attendu, la pile n’est pas vide, une autre méthode y a déjà renseigné une valeur …
En supprimant des tests, je suis tombée sur la méthode fautive en utilisant un point d’arrêt sur ce chemin , tout au fond d’un des tests d’intégration, dans une partie où EasyMock n’était pas du tout utilisée et sur des classes n’ayant aucun rapport avec les classes testées, il y avait quelque chose comme cela:
@Test
public void testJunitMalConstruit() {
FormatServiceImpl formatService = new FormatServiceImpl();
formatService.scale2((BigDecimal) anyObject());
}
Le « (BigDecimal) anyObject() » est ici une erreur d’étourderie qui au final se retrouve à avoir un impact très loin dans le code. C’est pour moi un bug d’EasyMock, même si ce « (BigDecimal) anyObject() » n’a rien à faire ici !
Le fait que les tests passent ou non dans Surefire ou dans Eclipse via « run as JUnit test » dépend en fait de l’ordre dans lequel les 2 lanceurs de tests ordonnent les différents tests. Pour enlever cette notion variable, on peut utiliser le test suivant :
public class CalculServiceImplTest {
private CalculServiceImpl calculService;
private FormatService formatServiceMock;
@Before
public void before() {
formatServiceMock = createMock(FormatService.class);
calculService = new CalculServiceImpl(
formatServiceMock);
}
@Test
public void testJunitMalConstruit() {
FormatServiceImpl formatService = new FormatServiceImpl();
formatService.scale2((BigDecimal) anyObject());
}
@Test
public void testAdd() {
BigDecimal a = BigDecimal.valueOf(5);
BigDecimal b = BigDecimal.valueOf(5);
BigDecimal c = BigDecimal.valueOf(10);
formatServiceMock.scale(eq(BigDecimal
.valueOf(10)));
replay(formatServiceMock);
calculService.addAndscale(a,
b);
verify(formatServiceMock);
}
}
Et là ca plante à chaque fois
Et pour faire plaisir aux adorateurs de Mockito, j’ai testé avec Mockito la classe ci-dessous :
public class CalculServiceImplMockitoTest {
private CalculServiceImpl calculService;
private FormatService formatServiceMock;
@Before
public void before() {
formatServiceMock = mock(FormatService.class);
calculService = new CalculServiceImpl(
formatServiceMock);
}
@Test
public void testJunitMalConstruit() {
FormatServiceImpl formatService = new FormatServiceImpl();
formatService.scale2((BigDecimal) anyObject());
}
@Test
public void testAdd() {
BigDecimal a = BigDecimal.valueOf(5);
BigDecimal b = BigDecimal.valueOf(5);
BigDecimal c = BigDecimal.valueOf(10);
formatServiceMock.scale(eq(BigDecimal
.valueOf(10)));
calculService.addAndscale(a,
b);
verify(formatServiceMock);
}
}
Et l’erreur est ici bien claire :
org.mockito.exceptions.misusing.InvalidUseOfMatchersException:
Misplaced argument matcher detected here:
-> at fr.java.freelance.easymock.CalculServiceImplMockitoTest.testJunitMalConstruit(CalculServiceImplMockitoTest.java:24)
You cannot use argument matchers outside of verification or stubbing.
Examples of correct usage of argument matchers:
when(mock.get(anyInt())).thenReturn(null);
doThrow(new RuntimeException()).when(mock).someVoidMethod(anyObject());
verify(mock).someMethod(contains("foo"))
Mockito 1 – EasyMock 0
PowerMock est une extension de 2 API bien connues des mockeurs (Ha ha), EasyMock et Mockito. Qui n’as jamais été obligé de supprimer un final, rendre une méthode private protected ou galérer sur des appels statiques pour faire ses tests ? PowerMock nous permet de « tester l’intestable » sans toucher au code. Bonne idée ? Oui, mais attention, cette bonne idée a un coût qu’il ne faut pas négliger. L’exécution des tests peut prendre jusqu’à 10 fois plus de temps.
De plus, si on ne fait pas attention, on peut tomber sur des anomalies qui peuvent être difficile à résoudre si on n’a pas saisi le « truc ». L’objet de cet article est de vous présenter ce qui me crash le plus souvent mes tests.
Le problème
Voici la classe à tester :
package fr.java.freelance;
public class UnTrucCool {
public final boolean estQuelqueChose(){
return critereUn() && critereDeux();
}
public boolean critereUn(){
return false;
}
public boolean critereDeux(){
return false;
}
}
En fait, un test existe déjà :
package fr.java.freelance;
import static org.junit.Assert.*;
import org.junit.Test;
import static org.mockito.Mockito.*;
public class UnTrucCoolTest {
@Test
public void testEstQuelqueChose() {
UnTrucCool banane = mock(UnTrucCool.class);
when(banane.critereDeux()).thenReturn(true);
when(banane.critereUn()).thenReturn(true);
assertTrue(banane.estQuelqueChose());
}
}
Pour une bonne raison, nous décidons d’utiliser PowerMock, nous modifions donc le test comme ceci :
package fr.java.freelance;
import static org.junit.Assert.*;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.powermock.core.classloader.annotations.PrepareForTest;
import org.powermock.modules.junit4.PowerMockRunner;
import static org.powermock.api.mockito.PowerMockito.*;
@RunWith(PowerMockRunner.class)
@PrepareForTest(UnTrucCool.class)
public class UnTrucCoolPMTest {
@Test
public void testEstQuelqueChose() {
UnTrucCool banane = mock(UnTrucCool.class);
when(banane.critereDeux()).thenReturn(true);
when(banane.critereUn()).thenReturn(true);
assertTrue(banane.estQuelqueChose());
}
}
Le test est strictement identique, mais ça ne fonctionne plus! estQuelqueChose() renvoie systématiquement false !
La solution
Dans le premier test nous utilisons simplement Mockito qui ne sait pas mocker les méthodes finales. Comme il ne sait pas le faire, il adopte un comportement par défaut et appel la méthode réelle. En passant à PowerMock, toutes les méthodes finales peuvent être mockées et doivent donc avoir un comportement défini explicitement. On notera que si estQuelquechose() n’avait pas été finale, le test Mockito aurait également dû définir explicitement le comportement à avoir.
@RunWith(PowerMockRunner.class)
@PrepareForTest(UnTrucCool.class)
public class UnTrucCoolPMTest {
@Test
public void testEstQuelqueChose() {
UnTrucCool banane = mock(UnTrucCool.class);
when(banane.critereDeux()).thenReturn(true);
when(banane.critereUn()).thenReturn(true);
when(banane.estQuelqueChose()).thenCallRealMethod();
assertTrue(banane.estQuelqueChose());
}
}
Faites attention lorsque vous passez un existant sur PowerMock.
]]>Cinq pôles principaux ont été abordés : les bonnes pratiques autour du déploiement, la supervision et le monitoring, la gestion des logs, la question de la robustesse et les bonnes pratiques organisationnelles. Seul le déploiement sera abordé dans cet article, la suite suivra !
Cyrille Le Clerc est architecte EE depuis 11 ans, dont 6 ans passé chez IBM Global Services et un peu plus de 3 ans chez Xebia.
Minimiser le nombre de composants à déployer
Au niveau du déploiement, la première bonne pratique est de minimiser le nombre de composants à déployer. Ce qui ne veut pas dire qu’il faut déployer des applications monolithiques mais bien qu’il est important de chercher et d’essayer de regrouper les composants de manière cohérente.
Il est courant pour le déploiement d’un unique EAR ou WAR de devoir dupliquer certains fichiers ou de devoir modifier certaines configuration sur d’autres serveurs. Chaque ‘micro-tâche’ de déploiement peut être source d’erreurs, moins il y en a plus il y a de chance que cela se passe bien ou que le retour en arrière soit aisé.
Ainsi, on peut retrouver la situation suivante : le contenu statique est contenu dans l’archive EAR avec l’ensemble du code nécessaire à l’application. Ce contenu statique sera dupliqué sur un serveur http simple dans une optique d’optimisation d’accès aux ressources statiques. On y accède via un filtrage des URLs en utilisant un mécanisme de routage en amont.

Cela fait donc 3 étapes pour une livraison :
- déploiement de l’application,
- déploiement des ressources statiques,
- mise à jour des règles de routages.
De plus, il est fréquent que le point de routage soit en plus sur un serveur mutualisé, ce qui augmente le risque d’impact de la mise à jour pour la web application déployée sur les autres applications dont les routes transitent par ce point de routage. La principale raison évoquée est le fait de gagner en performance.
La proposition de Cyrille est d’utiliser le mécanisme de proxy-cache http, pouvant être facilement mis en place par l’équipe infrastructure avec des outils tels que que Varnish Cache, squid, ibm Fast Response Cache Accelerator (FRCA) voir un simple module apache http comme mod_cache.
Il n’y a plus de déploiement des fichiers sur un serveur statique, plus de besoin de modifier les règles de routage.
Un autre exemple sur la nécessité du regroupement des différentes briques par cohérence est le double filtrage lié à la sécurité. Il est fréquent d’avoir en amont un premier filtrage par adresse IP puis dans un deuxième temps un filtrage sur un couple login/mot de passe. L’idée est dans ce cas de regrouper ses deux actions ensemble, que ce cela soit sur le firewall, en java ou autre mais à un même point . De plus, cela permet également de pouvoir faire un filtrage par login et par adresse IP en même temps c’est à dire de contrôler par exemple que le login ‘admin’ ne puisse être utilisée que par l’adresse IP X et l’adresse IP Y.
Cohabiter en bonne intelligence
Sur un même serveur physique
Le deuxième aspect du déploiement abordé est sur le fait de cohabiter en bonne intelligence. Au niveau de la cohabitation de plusieurs applications sur un même serveur, les recommandations sont simples :
Minimiser les répertoires absolus et faire en sorte que chaque fichier soit dans un répertoire préfixé par un identifiant d’application (possible d’utiliser le group id et l’artifact id du composant par exemple ou plus simple /etc/my-application.
Organiser l’utilisation des ports réseaux en séparant un préfixe definissant l’application et un suffixe définissant le service par exemple, si 100 correspond à l’application Facture, on aura le port du serveur http sur 10080, le port du SSL sur 10043. Cette séparation permet de faire cohabiter de manière organisée 100 applications.

Sur un même serveur d’application
En ce qui concerne la bonne cohabitation sur un même serveur d’application, il faut de la même manière minimiser les répertoires absolus (c’est à dire privilégier les chemins relatifs comme (${java.io.tmpdir}/my-app1/) et les rendre lisible en les préfixant par l’artifact id (et le group id si besoin) pour empêcher les collisions entre répertoire.
Cyrille recommande également de limiter au maximum les variables java statiques qui impactent l’ensemble du serveur, il vaut mieux les définir par application.
Au niveau des paramètres de configuration, la question est posée de savoir si il vaut mieux mettre les fichiers de configuration directement dans l’archive ou au contraire de les externaliser. La décision dépend de la situation, par exemple, si l’équipe d’exploitation ne désire pas que l’équipe de développement possède les accès base de données, la configuration se fera à l’extérieure de l’application.
Une autre recommandation au sujet des paramètres de configuration est de limiter le nombre de paramètres dont la valeur change suivant les environnements : en isolant ses réseaux virtuels, il est possible de conserver des noms de bases de données identiques, de conserver les noms de hosts.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Dans le cas où l’équipe d’exploitation propose d’utiliser des noms incluant par exemple les différents environnements ex : monappli-dev , monappli-rec, ma-bdd-dev, ma-bbd-rec il est possible de proposer un compromis avec la création d’alias. La multiplication des paramètres de configuration est souvent source de problème lors des déploiements. De même, il n’y a pas lieu de faire changer les ports d’écoute.
Cette recommandation impose qu’il n’y ait pas de perméabilité entre les zones de développement, de recette et de production. Dans une précédente mission, il suffisait d’utiliser foxy-proxy, plugin firefox de configuration de proxy pour switcher automatiquement de mon application web de prod vers mon application web d’homologation. Dans ce cas, l’homologation était fermée, impossible d’avoir accès à Internet par exemple. Il est également conseillé, par sécurité, de modifier par exemple le logo sur l’homologation ou de jouer avec des codes couleurs pour indiquer de manière visuelle l’environnement sur lequel on se trouve mais aussi d’ajouter un filtrage sur les ip appelantes (bloquer les ips ou changer les mots de passes). A l’aide des .profile, il est possible d’indiquer directement sur la console ‘prod’ ou ‘valid’, avec putty de changer les couleurs etc.
{kind=link}
Savoir ce qui est réellement déployé
Un autre point important du déploiement est de déployer des composants qui soient réellement traçables. On ne déploie que des composants taggés sur lesquels aucun commit n’aura été effectué (règle d’entreprise respectée/ utilisation de la fonctionnalité d’hook pour SVN) et/ou on empêche le redéploiement ( utilisation de la fonctionnalité Disable Redeployement de Nexus)) pour pouvoir connaître avec précision les classes déployées. Des outils comme Nexus ou Archiva permettent facilement de déployer des archives sur différents environnements en garantissant leur conformité.
Voilà les différents axes abordés sur la partie ‘déploiement’, la présentation, qui a durée 2 heures environ et a abordé 5 axes différents (seul le premier a été présenté ici), a été dense ! Pour ceux que cela intéresse plus en détails, Cyrille devrait publier ses slides dans quelques semaines et organisera à la mi mai une formation de 2 jours sur le thème. Pour le suivre sous twitter : @Cyrilleleclerc .
]]>
BigDecimal.equals vs BigDecimal.compareTo
Deux BigDecimaux qui ont la même valeur avec une précision différente ne sont pas considérés comme égaux à l’aide la méthode equals. En revanche, ils sont considérés comme égaux si on les compare avec la méthode compareTo.
Exemple :
BigDecimal bigDecimal1 = new BigDecimal(0);//0 BigDecimal bigDecimal2 = BigDecimal.ZERO;//0 BigDecimal bigDecimal3 = BigDecimal.valueOf(0.0);//0.0 System.out.println(bigDecimal1.equals(bigDecimal2)); //true System.out.println(bigDecimal1.equals(bigDecimal3)); //false System.out.println(bigDecimal2.equals(bigDecimal3)); //false System.out.println(bigDecimal1.compareTo(bigDecimal2)==0); //true System.out.println(bigDecimal1.compareTo(bigDecimal3)==0); //true System.out.println(bigDecimal2.compareTo(bigDecimal3)==0); //true
public int compareTo(BigDecimal val)
Compares this BigDecimal with the specified BigDecimal. Two BigDecimal objects that are equal in value but have a different scale (like 2.0 and 2.00) are considered equal by this method. This method is provided in preference to individual methods for each of the six boolean comparison operators (<, ==, >, >=, !=, <=). The suggested idiom for performing these comparisons is: (x.compareTo(y) <op> 0), where <op> is one of the six comparison operators.
public abstract
Dans un autre registre, quelque chose qui revient souvent dans le code :
Les termes public ou abstract dans la déclaration des méthodes d’une interface. L’ensemble des méthodes d’une interface sont obligatoirement public abstract, inutile donc de l’ajouter.
Mauvais nommage
Il y a toujours des variables mal nommées. Plusieurs raisons à cela :
- elles ne respectent pas les règles de nommage Java (variables en majuscule alors que non final static, présence de _ dans une variable local).
- le nom de la variable ne dépend de ce qu’elle fait : autant i,j,k sont des noms de variables admettables pour des compteurs au sein de boucle, pas ailleurs.
- le nom de la variable n’est pas compréhensible : updateFMTTTL si FMTTTL ne renvoie à rien fonctionnellement parlant, il faut lui donner un autre nom. Il vaut mieux une variable à nom long mais compréhensible plutôt qu’essayer de faire court. Ceux qui vous passeront derrière vous en remercieront !
Le livre Coder Proprement de Robert C Martin consacre plusieurs pages intéressantes sur ce sujet.
La concaténation de String
Exemple 1 : Avec utilisation de l’opérateur +
long start = System.currentTimeMillis();
String a = " Concaténation";
for (int i = 0; i < 10000; i++) {
a += i;
}
System.out.println(a);
System.out
.println(" in " + (System.currentTimeMillis() - start) + "ms");
Exemple 2 : Avec un StringBuilder
start = System.currentTimeMillis();
StringBuilder stringBuffer = new StringBuilder (" Concaténation");
for (int i = 0; i < 10000; i++) {
stringBuffer.append(i);
}
System.out.println(stringBuffer.toString());
System.out
.println(" in " + (System.currentTimeMillis() - start) + "ms");
Durée des 10000 concaténations :
Exemple 1 : 360ms
Exemple 2 : 15ms
Il a néanmoins des cas où il est préférable d’utiliser la concaténation de string (+ ou String.concat) :
pour aérer une ligne ex :
String myString = " line 1 "
+ "line 2";
pour strictement moins de 4 concaténation :
logger.debug("x :"+x+"y :"+y);
Le compilateur transforme automatiquement cettte ligne en utilisant un StringBuilder System.out.println((new StringBuilder()).append(« x: »).append(x).append( » y: »).append(y).toString());
Les tests avec les objets StringBuilder et StringBuffer renvoient des résultats quasiment similaires. StringBuilder étant un tout petit plus rapide, il est à utiliser le plus souvent possible. Le StringBuffer est quand à lui thread-safe donc à utiliser dans les environnements concurrents.
Il n’est pas forcément judicieux de remplacer toutes les concaténations de string automatiquement par un StringBuilder / StringBuffer. Si elles sont dans une boucle, le gain peut être remarquable dans les autres cas, cela se discute. Les StringBuilder / StringBuffer alourdissent considérablement la syntaxe et le gain est parfois très faible. Comme dans la plupart des cas, l’optimisation prématurée est à éviter ! Pour appronfondir le sujet, voir l’interview du Dr Heintz Kabutz : http://java.sun.com/developer/technicalArticles/Interviews/community/kabutz_qa.html
]]>Le domain driven design « Vite fait » : 80 pages pour changer votre vie. Ou plutôt changer votre façon d’écrire vos modèles métiers.
Cours sur la concurrence : Une piqure de rappel ne fait pas (de) mal.
Développer avec Comet et Java : Vous rêver d’envoyer des informations au navigateur en mode « push » ? Voici la solution.
Algodeal: Pour tous ceux qui aime inventer des algos, voici une occasion de faire fortune en s’amusant (et en java) !
Les castcodeurs : Episode spécial « Freelance » avec Mathilde ! A écouter absolument si vous souhaitez vous mettre indépendant !
]]>Dans la plupart des cas, pas de problème, la date est bien parsée et l’identifiant est crée conformément à ce que l’on attends. Néanmoins, dans de rares cas, il est possible que cela se passe beaucoup moins bien. En effet, la classe SimpleDateFormat n’est pas synchronisée. Si 2 threads essaient en même temps d’utiliser cette instance pour un parsage ou un formatage, le résultat est aléatoire.
La classe DateUtil a été simplifiée à l’extrême.
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateUtil {
public static final SimpleDateFormat simpleDateFormat = new SimpleDateFormat(
"ddMMyyyy");
public static final Date parse(String date) throws ParseException{
return simpleDateFormat.parse(date);
}
public static final String format(Date date) throws ParseException{
return simpleDateFormat.format(date);
}
}
La classe de test ci dessous fait en sorte que deux threads concurrents effectuent des parsages/formatages via les deux méthodes définies dans la classe DateUtil sur les trois dates de référence définies dans le tableau de String. Elle effectue ensuite une comparaison entre la date de référence et celle qui a été parsée+formatée.
import java.text.ParseException;
public class TestSimpleDateFormat {
public static void main(String[] args) {
final String[] tabDateString = new String[] {
"01012001", "08082008", "05052005" };
Runnable runnable = new Runnable() {
public void run() {
try {
for (int j = 0; j < 1000; j++) {
for (int i = 0; i < 2; i++) {
String date = DateUtil
.format(DateUtil
.parse(tabDateString[i]));
if (!(tabDateString[i].equals(date))) {
throw new ParseException(
tabDateString[i] + " =>"
+ date, 0);
}
}
}
} catch (ParseException e) {
e.printStackTrace();
}
}
};
new Thread(runnable).start();
Runnable runnable2 = new Runnable() {
public void run() {
try {
for (int j = 0; j < 1000; j++) {
for (int i = 0; i < 2; i++) {
String date = DateUtil
.format(DateUtil
.parse(tabDateString[i]));
if (!(tabDateString[i].equals(date))) {
throw new ParseException(
tabDateString[i] + " =>"
+ date, 0);
}
}
}
} catch (ParseException e) {
e.printStackTrace();
}
}
};
new Thread(runnable2).start();
}
}
Les résultats sont plus que divers, voilà ci dessous la liste des exceptions les plus fréquentes.
java.text.ParseException: 08082008 =>08012008 at TestSimpleDateFormat$1.run(TestSimpleDateFormat.java:19) at java.lang.Thread.run(Thread.java:619) java.text.ParseException: 01012001 =>08012001 at TestSimpleDateFormat$2.run(TestSimpleDateFormat.java:42) at java.lang.Thread.run(Thread.java:619) Exception in thread "Thread-1" java.lang.NumberFormatException: For input string: ".808E.8082E2" at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:1224) at java.lang.Double.parseDouble(Double.java:510) at java.text.DigitList.getDouble(DigitList.java:151) at java.text.DecimalFormat.parse(DecimalFormat.java:1303) at java.text.SimpleDateFormat.subParse(SimpleDateFormat.java:1934) at java.text.SimpleDateFormat.parse(SimpleDateFormat.java:1312) at java.text.DateFormat.parse(DateFormat.java:335) at TestSimpleDateFormat$2.run(TestSimpleDateFormat.java:40) at java.lang.Thread.run(Thread.java:619) Exception in thread "Thread-1" java.lang.NumberFormatException: multiple points at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:1084) at java.lang.Double.parseDouble(Double.java:510) at java.text.DigitList.getDouble(DigitList.java:151) at java.text.DecimalFormat.parse(DecimalFormat.java:1303) at java.text.SimpleDateFormat.subParse(SimpleDateFormat.java:1934) at java.text.SimpleDateFormat.parse(SimpleDateFormat.java:1312) at java.text.DateFormat.parse(DateFormat.java:335) at TestSimpleDateFormat$2.run(TestSimpleDateFormat.java:40) at java.lang.Thread.run(Thread.java:619) Exception in thread "Thread-1" java.lang.NumberFormatException: For input string: "" at java.lang.NumberFormatException.forInputString(NumberFormatException.java:48) at java.lang.Long.parseLong(Long.java:431) at java.lang.Long.parseLong(Long.java:468) at java.text.DigitList.getLong(DigitList.java:177) at java.text.DecimalFormat.parse(DecimalFormat.java:1298) at java.text.SimpleDateFormat.subParse(SimpleDateFormat.java:1934) at java.text.SimpleDateFormat.parse(SimpleDateFormat.java:1312) at java.text.DateFormat.parse(DateFormat.java:335) at TestSimpleDateFormat$2.run(TestSimpleDateFormat.java:40) at java.lang.Thread.run(Thread.java:619)
Bien sur, ces erreurs n’arrivent en réalité qu’exceptionnellement. Parfois, des exceptions sont remontées, parfois cela a l’air de bien se passer mais l’objet crée est en fait une combinaison d’autres dates et ne correspond donc pas à la date attendue. Il y a plusieurs manière de rendre la classe DateUtil thread safe.
Le plus simple, ne pas rendre l’objet simpleDateFormat comme étant un attribut de la classe mais de le recréer à chaque appel.
Ex :
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateUtil {
public static final Date parse(String date) throws ParseException{
SimpleDateFormat simpleDateFormat = new SimpleDateFormat(
"ddMMyyyy");
return simpleDateFormat.parse(date);
}
public static final String format(Date date) throws ParseException{
SimpleDateFormat simpleDateFormat = new SimpleDateFormat(
"ddMMyyyy");
return simpleDateFormat.format(date);
}
}
Dans le cas de méthodes communes, il est possible que cela deviennent couteux.
Une deuxième méthode est la définition des deux méthodes parse & format comme étant synchronized :
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateUtil {
public static final SimpleDateFormat simpleDateFormat = new SimpleDateFormat(
"ddMMyyyy");
public synchronized static final Date parse(String date) throws ParseException{
return simpleDateFormat.parse(date);
}
public synchronized static final String format(Date date) throws ParseException{
return simpleDateFormat.format(date);
}
}
Cette méthode marche, néanmoins, il est possible qu’elle crée un goulet d’étranglement du au fonctionnement de synchronized, les méthodes format & parse pouvant être extrêmement communes dans une application. Néanmoins, elle offre l’avantage d’être simple et claire.
Une approche un peu plus fine est l’utilisation d’un objet ThreadLocal. Cet objet permet d’utiliser des variables comme étant locale à un thread. Tous les threads ont une copie de la variable.
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateUtil {
private static ThreadLocal format = new ThreadLocal() {
protected synchronized SimpleDateFormat initialValue() {
return new SimpleDateFormat(
"ddMMyyyy");
}
};
private static SimpleDateFormat getSimpleDateFormat(){
return format.get();
}
public static final Date parse(String date) throws ParseException{
return getSimpleDateFormat().parse(date);
}
public static final String format(Date date) throws ParseException{
return getSimpleDateFormat().format(date);
}
}
Comme je suis dans le cas où ma classe DateUtil n’a besoin que d’une méthode format, j’ai choisi une 4ème méthode, l’utilisation non plus de l’objet java.text.SimpleDateFormat mais org.apache.commons.lang.time.FastDateFormat . Le formatage est supportée, avec le même pattern que pour la classe SimpleDateFormat à l’exception du z (se référer à la doc).
]]>Depuis le début de la crise économique mondiale, certains clients finaux ont diminué le nombre de prestataires et ont imposé des baisses de tarif importantes. Résultat : plus de prestataires et moins de mission, loi de l’offre et la demande oblige, les prix ont chuté d’environ 10%.
Pour ceux qui ont la chance d’être resté en mission ou qui n’ont pas vu leur tarif baisser, ce n’était pas le moment de changer. Et pour ceux qui ont subit, le risque est aujourd’hui de continuer à subir alors que le marché a repris. Alors comment avoir une vue globale sur le marché de la prestation Java en France ?
Personnellement j’utilise le baromètre du site hitechpros.com. Apprendre à décrypter ce baromètre permet de se faire une idée des tendances du marché.

Comment décrypter ces données ?
La courbe bleue correspond aux offres de missions (demandes des clients), ramenée à 100% elle sert de base. La courbe rouge correspond aux prestataires disponibles (offres de SSII). Donc plus la courbe rouge baisse, mieux c’est. Pour le mois de Mars, on y est, le nombre de prestataires disponibles est inférieur au nombre de missions ! Champagne !
Voici mon analyse en Mars 2010 :
– La crise est belle est bien terminée, cela fait plusieurs mois qu’on le pressentait avec le nombre d’offres de missions qui explose sur les différents sites d’emplois.
– Cette crise inversée ne va pas durer, les SSII vont se remettre à recruter en masse et le nombre de prestataire va remonter au dessus des offres de missions.
– Toutefois, le marché devrait rester en notre faveur jusqu’à la prochaine crise et les tarifs devraient augmenter fortement.
Mon conseil si vous n’êtes toujours pas freelance : foncez ! Le temps de démissionner les tarifs seront sur un nouveau « plus haut ». Si vous l’êtes déjà, c’est le moment de changer de mission si vous attendiez une accalmie. Sinon, attendez un peu que cette pénurie atteigne le client avant de demander une revalorisation importante de votre tarif.
Ce qu’était mon analyse fin 2009 :
– Actuellement le nombre d’intercontrat baisse fortement et les clients commencent à avoir du mal à trouver des ressources. Les indépendants trouvent facilement des missions mais mal payées.
– Si la tendance se confirme, les SSII vont recommencer à recruter afin de répondre aux exigences des clients, les débutants et chômeurs vont réussir à trouver du travail mais moins bien payé qu’avant 2007, car les tarifs n’auront pas encore remontés.
– Lorsque le vivier d’inter-contrats et de jeunes diplômés sera absorbé, les prix commenceront à remonter et les salaires feront de même. Il sera temps pour les indépendants de profiter de cette dynamique avant la prochaine crise.
Pour conclure, n’oubliez pas que le meilleur moyen de rester employable, crise ou pas crise est de se former ! En mission comme à la maison ou en dehors. Ainsi que de bien choisir ses missions ! Pas forcément chercher une « niche rentable » mais faire quelquechose qui nous passionne est le meilleur moyen d’y exceller.
Et vous comment vivez vous ou avez vous vécu cette crise ? Quelle est votre stratégie pour les mois à venir ?
]]>Lorsque l’on met en place les mocks, il est fréquent que l’on ait besoin de tester qu’un objet créé à l’intérieur de la méthode testée correspond bien à ce que l’on attend, cet objet étant passé en tant que paramètre à une méthode d’un objet mocké.
Prenons pour exemple, la classe Service et sa méthode processRequest. La méthode processRequest prend en entrée deux paramètres et se sert de ces paramètres pour créer un objet Bond, qui sera passé ensuite à la méthode persist du service BondDao.
package fr.java.freelance.easymock;
import java.math.BigDecimal;
public class Service {
private BondDao bondDao;
public String processRequest(String name,BigDecimal quantity) {
Bond bond = new Bond(name,quantity);
return bondDao.persist(bond);
}
public void setBondDao(BondDao bondDao) {
this.bondDao = bondDao;
}
}
package fr.java.freelance.easymock;
public interface BondDao {
String persist(Bond bond);
}
package fr.java.freelance.easymock;
import java.math.BigDecimal;
public class Bond {
private String name;
private BigDecimal quantity;
public Bond(String name, BigDecimal quantity) {
super();
this.name = name;
this.quantity = quantity;
}
public String getName() {
return name;
}
public BigDecimal getQuantity() {
return quantity;
}
}
Il est a priori impossible pour un test unitaire d’accèder à l’objet « bond » pour le vérifier.
Ce que l’on cherche à garantir, c’est que la méthode processRequest construit un objet de type Bond ayant comme attributs name et quantity les 2 valeurs passées en paramètres, qu’elle le transmette à la méthode persist de ServiceDao et retourne le paramètre de retour de cette méthode persist.
Utilisation d’EasyMock.anyObject()
La première méthode pour tester ceci est d’utiliser la méthode anyObject de l’objet EasyMock.
Service service = new Service(); BondDao bondDaoMock = EasyMock.createMock(BondDao.class); service.setBondDao(bondDaoMock); final String persist_return = "123AX"; final String name = "Name 5%"; final BigDecimal quantity = BigDecimal.TEN; EasyMock.expect(bondDaoMock.persist((Bond) EasyMock.anyObject())) .andReturn(persist_return); EasyMock.replay(bondDaoMock); String idInternal = service.processRequest(name, quantity); Assert.assertEquals(persist_return,idInternal); EasyMock.verify(bondDaoMock);
Le test fonctionne, néanmoins rien ne garantit que l’objet que l’on transmet à la méthode persist de BondDao est conforme à ce que l’on attend.
Pour pouvoir analyser l’objet Bond transmis, il existe plusieurs possibilités, dont une utilisant la redéfinition de la méthode equals de l’objet Bond et deux fournies par la librairie EasyMock, l’utilisation d’un IArgumentMatcher ou de EasyMock.capture.
Rédéfinition de la méthode equals()
Supposons que l’objet bond redéfinisse la méthode equals de manière à tester l’égalité des paramètres name et quantity.
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Bond other = (Bond) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (quantity == null) {
if (other.quantity != null)
return false;
} else if (quantity.compareTo(other.quantity)!=0)
return false;
return true;
}
Il suffit alors d’écrire le test suivant pour garantir que l’objet passé à la méthode persist est bien égal au bond attendu :
@Test
public void testProcessRequestWithEquals() {
Service service = new Service();
BondDao bondDaoMock = EasyMock.createMock(BondDao.class);
service.setBondDao(bondDaoMock);
final String persist_return = "123AX";
final String name = "Name 5%";
final BigDecimal quantity = BigDecimal.TEN;
final Bond bondExpected = new Bond(name,quantity);
EasyMock.expect(bondDaoMock.persist(bondExpected))
.andReturn(persist_return);
EasyMock.replay(bondDaoMock);
String idInternal = service.processRequest(name, quantity);
Assert.assertEquals(persist_return,idInternal);
EasyMock.verify(bondDaoMock);
}
Cette démarche est la plus naturelle, néanmoins elle ne s’applique pas dans le cas où la méthode equals n’est n’ai pas redéfinie (dans ce cas, c’est la méthode equals de Object qui est prise en compte et donc, les deux objets ne seraient pas égaux (pas la même instance)). Elle ne s’applique pas non plus dans le cas où la méthode equals ne correspondrait pas à ce que l’on a définit comme étant utile pour tester l’égalité. Par exemple une méthode equals qui ne testerait que l’égalité de l’attribut name dans l’objet Bond alors que nous souhaitons garantir les valeurs des deux paramètres. On ne peut évidement pas modifier la méthode equals d’un objet pour le tester, cela changerai son comportement !!
Il faut donc se tourner vers d’autres solutions.
Utilisation d’un IArgumentMatcher
EasyMock permet d’utiliser un certain nombre de matcher déjà définit ( eq, isNull, matches ..). Néanmoins dans le cas présent, il nous faut définir notre propre matcher pour pouvoir tester l’égalité des paramètres name et quantity.
La redéfinition d’un matcher s’effectue en deux temps.
D’abord, il faut créer une classe implémentant IArgumentMatcher.
package fr.java.freelance.easymock;
import org.easymock.EasyMock;
import org.easymock.IArgumentMatcher;
public class BondEquals implements IArgumentMatcher {
private final Bond expected;
public BondEquals(Bond expected) {
this.expected = expected;
}
public boolean matches(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (expected.getClass() != obj.getClass())
return false;
Bond other = (Bond) obj;
if (this.expected.getName() == null) {
if (other.getName() != null)
return false;
} else if (!this.expected.getName().equals(other.getName()))
return false;
if (this.expected.getQuantity() == null) {
if (other.getQuantity() != null)
return false;
} else if (this.expected.getQuantity().compareTo(other.getQuantity()) != 0)
return false;
return true;
}
public void appendTo(StringBuffer buffer) {
buffer.append("eqException ").append(expected.toString());
}
public static Bond eqBond(Bond in) {
EasyMock.reportMatcher(new BondEquals(in));
return null;
}
}
Pour pouvoir utiliser le BondEquals ainsi crée, la méthode persist de l’interface BondDao n’acceptant que les objets de type Bond, on utilise l’astuce suivante :
public static Bond eqBond(Bond in) {
EasyMock.reportMatcher(new BondEquals(in));
return null;
}
On peut alors utiliser le test suivant, pour garantir d’une part le bon retour de la méthode processRequest ainsi que le passage du bond ayant les caractéristiques souhaitées à la méthode persist du BondDao.
@Test
public void testProcessRequestWithArgumentMatcher() {
Service service = new Service();
BondDao bondDaoMock = EasyMock.createMock(BondDao.class);
service.setBondDao(bondDaoMock);
final String persist_return = "123AX";
final String name = "Name 5%";
final BigDecimal quantity = BigDecimal.TEN;
final Bond bondExpected = new Bond(name,quantity);
EasyMock.expect(bondDaoMock.persist(BondEquals.eqBond(bondExpected)))
.andReturn(persist_return);
EasyMock.replay(bondDaoMock);
String idInternal = service.processRequest(name, quantity);
Assert.assertEquals(persist_return,idInternal);
EasyMock.verify(bondDaoMock);
}
Utilisation de org.easymock.Capture
Une autre méthode consiste à capturer l’objet bond passé à la méthode persist du DAO et de faire des tests dessus dans un deuxième temps.
Une capture s’effectue en 3 temps.
1. Déclaration de la capture : Capture capture = new Capture();
2. Capture du paramètre lors de l’exécution via : EasyMock.expect(bondDaoMock.persist(EasyMock.and(EasyMock.isA(Bond.class), EasyMock.capture(capture))))
3. Récupération de l’objet capturé : Bond captured = capture.getValue();
@Test
public void testProcessRequestWithCapture() {
Service service = new Service();
BondDao bondDaoMock = EasyMock.createMock(BondDao.class);
service.setBondDao(bondDaoMock);
final String persist_return = "123AX";
final String name = "Name 5%";
final BigDecimal quantity = BigDecimal.TEN;
Capture capture = new Capture();
EasyMock.expect(bondDaoMock.persist(EasyMock.and(EasyMock
.isA(Bond.class), EasyMock.capture(capture))))
.andReturn(persist_return);
EasyMock.replay(bondDaoMock);
String idInternal = service.processRequest(name, quantity);
Assert.assertEquals(persist_return,idInternal);
Bond captured = capture.getValue();
Assert.assertEquals(name,captured.getName());
Assert.assertTrue(quantity.compareTo(captured.getQuantity())==0);
EasyMock.verify(bondDaoMock);
}
Il existe également d’autres méthodes utilisant des outils externes pour atteindre un but similaire mais je n’ai pas encore trouvé de limitation à la création d’un nouveau matcher ou la capture de l’élément à tester. Si il y a besoin plusieurs fois de tester l’objet de manière identique, j’ai tendance à créer un nouveau matcher et à utiliser la capture dans le cadre d’objets plus petits ou de besoin spécifique à un test.
]]> Un nouveau groupe autour de Java se lance en France ! DuchessFr est un groupe destiné à mettre en relation et à promouvoir les femmes dans le monde du développement Java. Originaire des Pays Bas, JDuchess s’étend petit à petit avec des antennes en France et au Brésil.
Un nouveau groupe autour de Java se lance en France ! DuchessFr est un groupe destiné à mettre en relation et à promouvoir les femmes dans le monde du développement Java. Originaire des Pays Bas, JDuchess s’étend petit à petit avec des antennes en France et au Brésil.
Les actions menées en France seront de plusieurs types :
– La création d’un réseau virtuel, via twitter, linkedin, une mailing list …
– Inciter les femmes à participer à des évènements locaux, comme les soirées JUG ou les autres conférences.
– Se rencontrer pour échanger, avant ou après les soirées JUGs, autour d’un apéro ou d’un repas.
– Lister les différents évènements en France pour ne pas les rater et éventuellement trouver quelqu’un avec qui y aller.
Pour se tenir informer des évènements de ce groupe, vous pouvez nous rejoindre sur twitter @duchessfr , sur LinkedIn ou via notre mailing list.
Le premier évènement aura lieu le 9 mars à 18h30 , juste avant le paris JUG au Vavin Café (18 rue Vavin 75006 Paris). Lorsque vous serez inscrites au JUG, contactez ellene(dot)dijoux(at)jduchess(dot)org qui vous accueillera Mardi prochain.
]]> Hier soir avait lieu les 2 ans du Paris JUG. Le Paris JUG est le premier Java User Group crée en France, beaucoup d’autres régions ont désormais le leur. L’association a été crée en février 2008 et réunit une fois par mois pas loin de 200 personnes dans les locaux de l’ISEP pour des sujets plutôt techniques (Performance, Qualité de code, EE6 …). Niveau formation continue, retour d’expérience et construction de réseaux, c’est un des lieux où il faut être, chaque 2ème mardi du mois.
Hier soir avait lieu les 2 ans du Paris JUG. Le Paris JUG est le premier Java User Group crée en France, beaucoup d’autres régions ont désormais le leur. L’association a été crée en février 2008 et réunit une fois par mois pas loin de 200 personnes dans les locaux de l’ISEP pour des sujets plutôt techniques (Performance, Qualité de code, EE6 …). Niveau formation continue, retour d’expérience et construction de réseaux, c’est un des lieux où il faut être, chaque 2ème mardi du mois.
Le Paris JUG c’est aussi une ‘troisième mi-temps’ dans un bar-resto après la soirée. Me retrouver après les confs pour discuter avec des passionnés sur des sujets variés (mise en place de pair programming, Groovy, se lancer en freelance …) est vraiment une composante importante de mon intérêt pour le Paris JUG !
Pour la soirée d’hier, les choses avaient été faites en grand : amphi de 500 places, bien rempli, goodies, présence de stands, buffet, énormément de gens venus de partout dont pas mal rencontrés à Devoxx. Au niveau des sujets, la keynote d’ouverture de Sacha Labourey abordait le thème ‘la révolution open-source a t elle eu lieu ?’. Se sont suivis ensuite quelques questions/réponses à Sacha et Marc Fleury, invité surprise de la soirée et fondateur de Jboss. La notion de ‘passion’ a pour la première fois été abordée et il faut reconnaître, et tous les intervenants l’ont fait lors de la soirée, que s’investir dans l’open-source est chronophage et avant tout, une affaire de passion.
Quelques business models de projets Open Source (Acceleo, XWiki, eXo Platform) ont été présentés sur la forme de quickies par les différents acteurs de ces projets, permettant de donner des exemples concrets à la keynote plus générale de Sacha. Des outils open-source (jCaptcha, jax-doclets, Play!) ont eu également le droit à leurs quickies, plus techniques.
Jean-Michel Doudoux, architecte Sfeir Benelux , a également parlé de son travail de rédaction et du choix de la license autour de Développons en Java, quelques 1888 pages en français, le tout sur 10 ans, mis à jour désormais 3 à 4 fois par ans et qui correspond à une véritable bible, en français sur le langage Java : http://www.jmdoudoux.fr/accueil_java.htm#dej . Les prochaines évolutions seront sur JEE, Android ! Un travail titanesque pour lequel il a choisit la license GNU FDL, bien conscient des problèmes pour faire valoir ses droits dès que l’on publie sur le net.
La présentation sur le framework Play! était vraiment bien mené et a éveillé pas mal les curiosités ! Ce framework web, fait par des développeurs web constitue une alternative pour développer sur une architecture REST. Ce framework permet entre autre un rechargement à chaud (la démo est faite via un simple éditeur de texte), le code modifié impactant immédiatement l’appli web, un système de gestion des exceptions à l’écran, un système de templating, avec la possibilité de créer ses propres tags ou d’utiliser le système d’expression langage de groovy et beaucoup d’autres choses encore.
Pour avoir plus d’infos : http://www.playframework.org/
Pour avoir le détail des conférences, Olivier Croisier a très bien retranscrit tout le détail dans son blog http://thecodersbreakfast.net/index.php?post/2010/02/05/Suivez-le-Paris-JUG-anniversaire-en-live !
La troisième mi-temps s’est déroulé au Dome dans le 17ème avec petits fours. J’ai eu l’occasion de discuter avec Nicolas Leroux (contributeur) et Guillaume Bort (lead developper) autour de Play! , principalement sur l’utilisation en industrie et des questions plus techniques. On en a également profité pour parler d’un projet de réseautage de la communauté féminine de Java, j’en parlerai plus en détail quand cela sera avancé mais c’était agréable de voir du monde réunis autour de la table !