Une des grandes idées des architectures orientées data (Buzz words : OpenData, BigData) est de laisser la possibilité de poser des questions, inconnues aujourd’hui mais qui pourront s’exécuter demain sur les données d’aujourd’hui. Pour cela il suffit “simplement” de stocker les données plutôt qu’un état (calculé à partir des données).
Qu’est ce que la data ?
Une idée reçue est que la data est ce qui est stocké en base de données. Voici un exemple simple d’interaction avec un site web :

La data, (ou les données) sont toutes les informations immuables que nous pouvons récolter, dans cette exemple il s’agit des actions exercées sur notre site. Les données, ce sont des faits, des vérités, et non pas des états calculés.
Cas d’utilisation des data
Dans une application classique, seul l’état est stocké en base, et il est possible de poser des questions au système, par exemple : combien il y a t’il de profils sur mon site ? Qui est coach Agile ? etc.
En revanche, certaines questions seront impossibles à poser au système ou retourneront un résultat erroné :
-
Combien de personnes connaissent Java ? (L’info est perdu pour Vincent).
-
Combien de commentaires Vincent à t’il reçu ? ( 2 en réalité)
-
Qui crée des profils factices pour augmenter artificiellement son nombre de commentaires ? (Pour cette question il faudrait stocker des informations techniques et faire des recoupements, conserver une trace des comptes supprimés etc..)
Et, plus amusant des questions utilisant des données externes, telle que la météo par exemple :
-
Quel temps fait il le plus souvent lorsqu’un profil et créé ? Lorsqu’il est supprimé ?
Ce genre de questions peutt être utile pour des scientifiques dans des domaines tels que l’anthropologie !
Ou pas ! En réalité, il est difficile de prévoir comment les données vont être utilisées demain. Peut être pour proposer une fonctionnalité de recommendation poussée, ajouter une nouvelle statistique pour analyser les futures campagnes marketing d’Hopwork par exemple… Qui sait ? Ce que nous savons en revanche, c’est qu’il faut absolument, non pas stocker simplement un état calculé mais bien l’ensemble des données du site afin de pouvoir nous en servir dans le futur.
Mise en oeuvre technique
Pour mettre en oeuvre nos cas d’usages et les cas d’utilisations futurs et encore inconnus, nous allons rencontrer de nombreux problèmes techniques :
-
Stockage des données : Stocker l’ensemble des faits plutôt qu’un état demande beaucoup plus d’espace de stockage et cet espace augmente constamment dans le temps même si la base des utilisateurs reste fixe. Elle augmente donc à la fois dans le temps et en fonction du nombre d’utilisateur et aussi du nombre de fonctionnalités qui s’ajoute au fur et à mesure de la vie d’une application.
-
Performance lors du requêtage : Une base de données de faits n’est pas optimisé pour poser des questions. Par exemple, pour connaître le nombre de commentaires visibles de Vincent nous sommes obligé de relire tous les faits liés à Vincent. Et ce nombre de faits augmente sans cesse, le temps de calculer une réponse sur ces faits sera de plus en plus long et coûteux.
-
Véracité des faits : Les faits ne doivent jamais être corrompus sans quoi il serait impossible de calculer un état stable du système et nos données ne serviraient plus rien. L’avantage des faits est qu’on ne les change jamais, on se prémunit ainsi des erreurs humaines (ie des algorithmes comportant des bugs). Il ne reste donc plus qu’a se protéger des erreurs machines (coupure électrique, pannes etc..)
Pour résoudre le problème du stockage, il faut mettre en place des solutions de système de fichiers distribués. Il en existe sur le marché, Hadoop par exemple. Afin de garantir la véracité des faits, il nous faut un système qui ne tombe jamais en panne, pour cela nous pouvons nous orienter vers des systèmes redondants telle que mis en oeuvre dans le cloud.
Pour résoudre les problèmes de performance nous pouvons mettre en oeuvre une “lambda architecture”.
Lambda Architecture
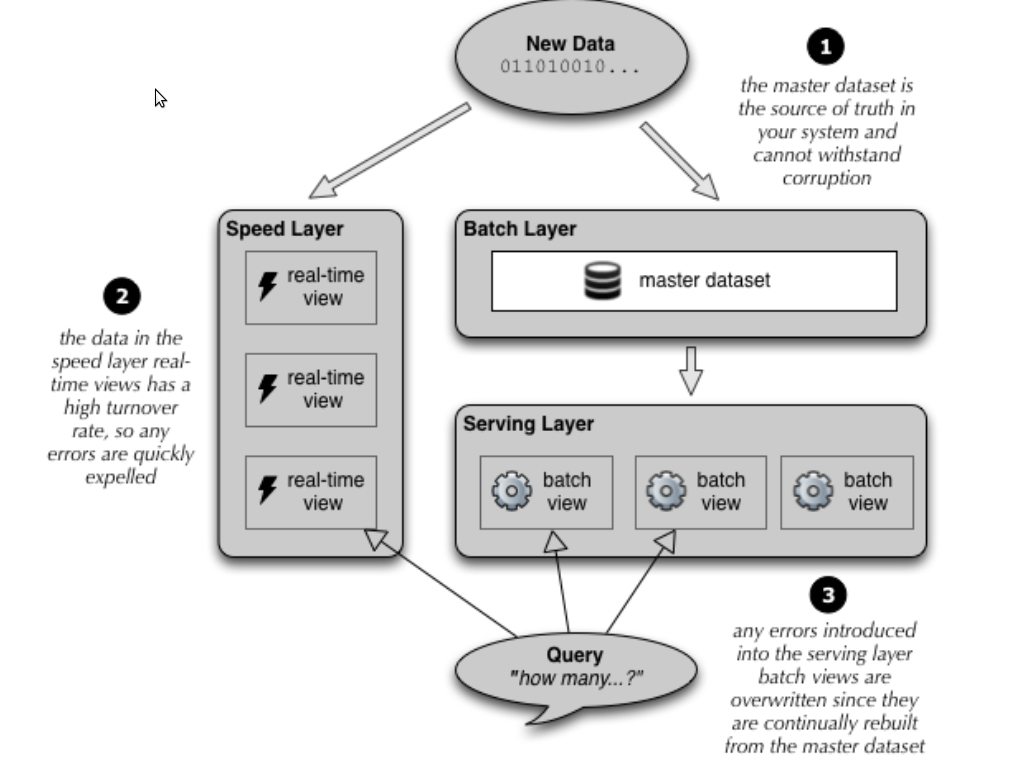
Tiré du livre « BigData » des éditions Manning
Lorsqu’une donnée entre dans le système (une action sur le site par exemple), elle est :
- traitée par les speeds layers afin de recalculer au fil de l’eau les vues « optimisées pour la lecture ». Idéalement on cherchera à atteindre une complexité constante en lecture pour chaque vue quitte à faire un calcul inexacte lorsque cela est acceptable. Comme la vue est déjà précalculé depuis l’état N-1, il est le plus souvent possible de la mettre à jour avec une complexité constante également. On s’est amusé ici avec des bases orienté lecture (SQL, Mongo, Redis etc..) ainsi que des architectures à base de composants et de queues (JMS, Akka etc.)
- stockée en parallèle dans notre base de faits (Batch layer). En mode ‘append only’. Là encore il faut viser une complexité d’écriture constante. On pourra s’amuser à utiliser Cassandra qui à l’avantage de nous permettre de stocker les faits ordonnés, ce qui peut se réveler très utiles pour recalculer nos vues à partir d’un instant T ou tout simplement pour le parcours des données. On pourra également stocker les données dans Hadoop, tout dépendra de la nature de celles-ci et de ce qu’on veut en faire.
Le serving layer permet de calculer les vues à partir de la base de faits. Il a toujours un temps de retard mais garantie des snapshots du système précis. Il suffit pour les speeds layers de rejouer les données entre un snapshot et le présent pour se « mettre à jour ».
Ainsi en cas de bug détecté à la fois sur le speed layer et le batch layer, il suffit livrer le code corriger du speed layer, recalculer depuis la snapshot qui correspond à la mise en prod du bug jusqu’à aujourd’hui avec les servings layers, puis serving ce snapshot au speeds layers qui recalculeront depuis ce snapshot jusqu’au nouveau présent. Il est donc inutile de couper le site pendant 5 jours, le temps de reprendre les données (je dit ça car c’est du vécu).
En résumé
En tant que professionnel, il du plus mauvais effet de devoir dire à un client qu’on a perdu des informations, à cause d’un système basé sur des updates. Une application basique se contente souvent de n’avoir que des speed layers et des vues. Lassé de paraître ridicule quand on nous demande ce qu’il se passe sur notre système, on y ajoute un système de log déstructuré qui est souvent insuffisant.
Aussi, les bugs corrompent les données et il est parfois impossible de les restaurer.
Finalement, mettre une place une architecture orienté data est plus couteuse qu’une application basique mais elle rend obsolète le besoin de logguer et permet de faire infiniement plus de choses, comme la restauration du système lorsqu’un bug a corrompu les vues, et la possibilité d’ajouter des fonctionnalités d’historique qui fonctionneront sur les données du passé.
Pour creuser le sujet, je vous conseille de lire l’excellent livre : Big Data

]]>